NOTE: I was starting my 6th build when I realized the log links are not publicly accessible. Sorry about that: https://pkg02.int.unixathome.org/ should not resolve for you.
I have a new server in the basement, known as r7425-01 – it’s beefy. It’s newer than the other hosts I have. Should I retire one of the older servers?
First, let’s see if it’s faster. My primary use case: building packages via poudriere.
In this post:
- FreeBSD 15.0
- poudriere-3.4.8
- I’ll compare how various poudriere.conf configuration settings affect the time to build all my packages
- How does this jail (pkg02) compare against my original jail (pkg01)? The hosts are quite different.
- The new host is using only HDD – I’ll eventually add in some SSD as part of this testing.
- Graphs are taken from LibreNMS which pulls data via snmpd
I’ve seen recommendations for various settings and they are rarely accompanied by any data. I’m sure they all help, but am I getting a small boost or a big boost?
The configuration
This is what I was using for the initial build. I’ve opted to strip out comments and blank lines, and then sort the results. This makes it easier for me to compare two separate configurations.
grep -v '^#' poudriere.conf | grep -v '^$' | sort > poudriere.conf.stripped.sorted
This is what pkg02 was running with for the initial run:
[12:02 pkg02 dvl /usr/local/etc] % cat poudriere.conf.stripped.sorted # # This was the intial run for pkg02 # BASEFS=/usr/local/poudriere DISTFILES_CACHE=/usr/ports/distfiles FREEBSD_HOST=_PROTO_://_CHANGE_THIS_ RESOLV_CONF=/etc/resolv.conf USE_PORTLINT=no USE_TMPFS=yes ZPOOL=data01
When you compare it to what pkg01 is using, it is significantly different. The first three lines alone should speed things up.
[12:03 pkg02 dvl /usr/local/etc/pkg01-conf] % cat poudriere.conf.stripped.sorted # grep -v '^#' poudriere.conf | grep -v '^$' > poudriere.conf.sorted # created via: ALLOW_MAKE_JOBS=yes ALLOW_MAKE_JOBS_PACKAGES="pkg ccache py* llvm* mongodb* cmake binutils samba* gdb mysql*-server png graphviz gcc* sdocbook rust vaultwarden librenms ghc" ALLOW_UNSUPPORTED_SYSTEM=1 BASEFS=/usr/local/poudriere BUILD_AS_NON_ROOT=yes CCACHE_DIR_NON_ROOT_SAFE=no COMMIT_PACKAGES_ON_FAILURE=yes DISTFILES_CACHE=/usr/ports/distfiles FREEBSD_HOST=https://download.FreeBSD.org GIT_BASEURL=git.freebsd.org/ports.git PKG_REPO_SIGNING_KEY=/usr/local/etc/ssl/pkg.key RESOLV_CONF=/etc/resolv.conf SVN_HOST=svn0.us-east.FreeBSD.org URL_BASE=https://services.unixathome.org/poudriere USE_PORTLINT=yes USE_TMPFS="all" ZPOOL=data03 ZROOTFS=/poudriere
Look how flat the CPU usage is.
insert CPU screen shot here = I’m having trouble uploading images.
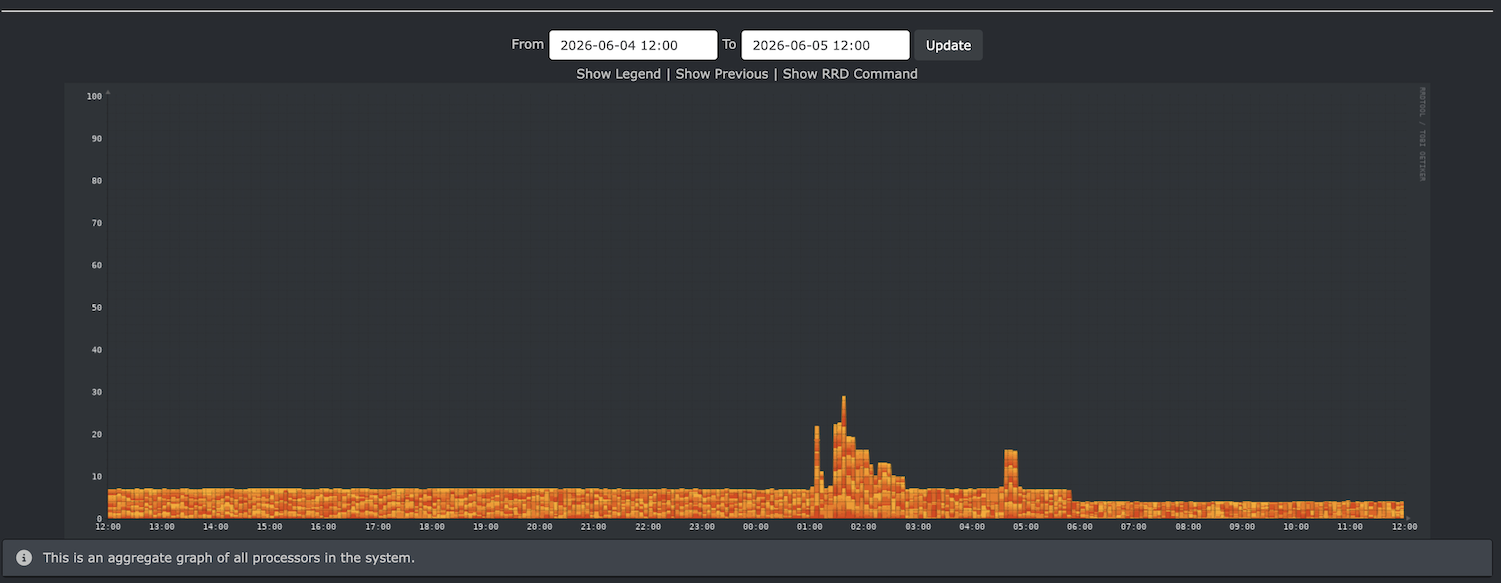
All up, this build took 29:08:12 plus the original build of … 11:24:19. That’s 40.5 hours, more or less.
I’m sure some of that time was fetching data. I am also sure that I should repeat my original build with -c added.
sudo poudriere bulk -j 150amd64 -p default -z primary -cf /usr/local/etc/poudriere.d/buildlists/primary
That will “Clean all previously built packages and logs” and build from scratch.
What a mess – it’s cleanup time
Here, I have this:
[18:11 pkg02 dvl /usr/local/etc/nginx] % zfs list NAME USED AVAIL REFER MOUNTPOINT data01 15.6G 65.3T 96K /data01 data01/poudriere 13.3G 65.3T 112K /data01/poudriere data01/poudriere/data 3.89G 65.3T 136K /data01/poudriere/data data01/poudriere/data/.m 96K 65.3T 96K /data01/poudriere/data/.m data01/poudriere/data/cache 27.9M 65.3T 27.9M /data01/poudriere/data/cache data01/poudriere/data/images 96K 65.3T 96K /data01/poudriere/data/images data01/poudriere/data/logs 51.5M 65.3T 51.5M /data01/poudriere/data/logs data01/poudriere/data/packages 3.81G 65.3T 3.81G /data01/poudriere/data/packages data01/poudriere/data/wrkdirs 96K 65.3T 96K /data01/poudriere/data/wrkdirs data01/poudriere/distfiles 6.88G 65.3T 6.88G /usr/ports/distfiles data01/poudriere/jails 1.50G 65.3T 96K /data01/poudriere/jails data01/poudriere/jails/150amd64 1.50G 65.3T 1.50G /usr/local/poudriere/jails/150amd64 data01/poudriere/ports 1.02G 65.3T 96K /data01/poudriere/ports data01/poudriere/ports/default 1.02G 65.3T 1.02G /usr/local/poudriere/ports/default
I have to fix this up.
After fixing
It took a while, but this is looking better:
[18:57 pkg02 dvl ~] % zfs list NAME USED AVAIL REFER MOUNTPOINT data01 15.6G 65.3T 96K /data01 data01/poudriere 13.3G 65.3T 112K /usr/local/poudriere data01/poudriere/data 3.89G 65.3T 136K /usr/local/poudriere/data data01/poudriere/data/.m 96K 65.3T 96K /usr/local/poudriere/data/.m data01/poudriere/data/cache 27.9M 65.3T 27.9M /usr/local/poudriere/data/cache data01/poudriere/data/images 96K 65.3T 96K /usr/local/poudriere/data/images data01/poudriere/data/logs 51.5M 65.3T 51.5M /usr/local/poudriere/data/logs data01/poudriere/data/packages 3.81G 65.3T 3.81G /usr/local/poudriere/data/packages data01/poudriere/data/wrkdirs 96K 65.3T 96K /usr/local/poudriere/data/wrkdirs data01/poudriere/distfiles 6.88G 65.3T 6.88G /usr/ports/distfiles data01/poudriere/jails 1.50G 65.3T 96K /usr/local/poudriere/jails data01/poudriere/jails/150amd64 1.50G 65.3T 1.50G /usr/local/poudriere/jails/150amd64 data01/poudriere/ports 1.02G 65.3T 96K /usr/local/poudriere/ports data01/poudriere/ports/default 1.02G 65.3T 1.02G /usr/local/poudriere/ports/default [18:57 pkg02 dvl ~] % sudo zfs set mountpoint=none data01 cannot set property for 'data01': permission denied [18:57 pkg02 dvl ~] % ls -l /usr/local/poudriere total 10 drwxr-xr-x 8 root wheel 8 2026.06.03 23:46 data/ drwxr-xr-x 3 root wheel 3 2026.06.05 18:39 jails/ drwxr-xr-x 3 root wheel 3 2026.06.05 18:39 ports/ [18:57 pkg02 dvl ~] % cd /usr/local/poudriere [18:57 pkg02 dvl /usr/local/poudriere] % ls -l data total 3 drwxr-xr-x 3 root wheel 3 2026.06.04 00:00 cache/ drwxr-xr-x 2 root wheel 2 2026.06.03 23:46 images/ drwxr-xr-x 3 root wheel 3 2026.06.03 23:55 logs/ drwxr-xr-x 3 root wheel 3 2026.06.03 23:55 packages/ drwxr-xr-x 2 root wheel 2 2026.06.03 23:46 wrkdirs/ [18:57 pkg02 dvl /usr/local/poudriere] % ls -l jails total 9 drwxr-xr-x 18 root wheel 21 2026.06.03 23:50 150amd64/ [18:57 pkg02 dvl /usr/local/poudriere] % ls -l ports total 9 drwxr-xr-x 72 root wheel 84 2026.06.03 23:57 default/ [18:57 pkg02 dvl /usr/local/poudriere] %
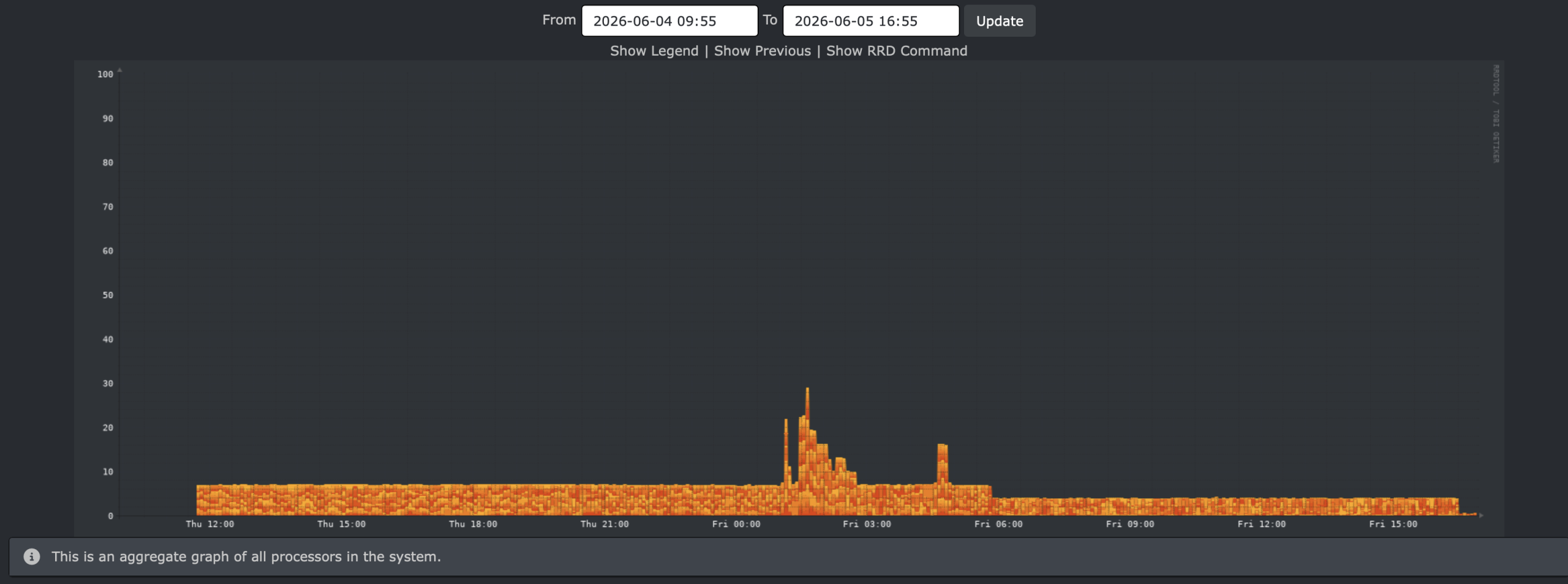
Second run
My next run was 30:50:23 – that’s 10 hours less. I’m not sure why.
Here’s the graph for that one:
Let’s do another one.
Third run
The third run took 30:49:44
The graph:
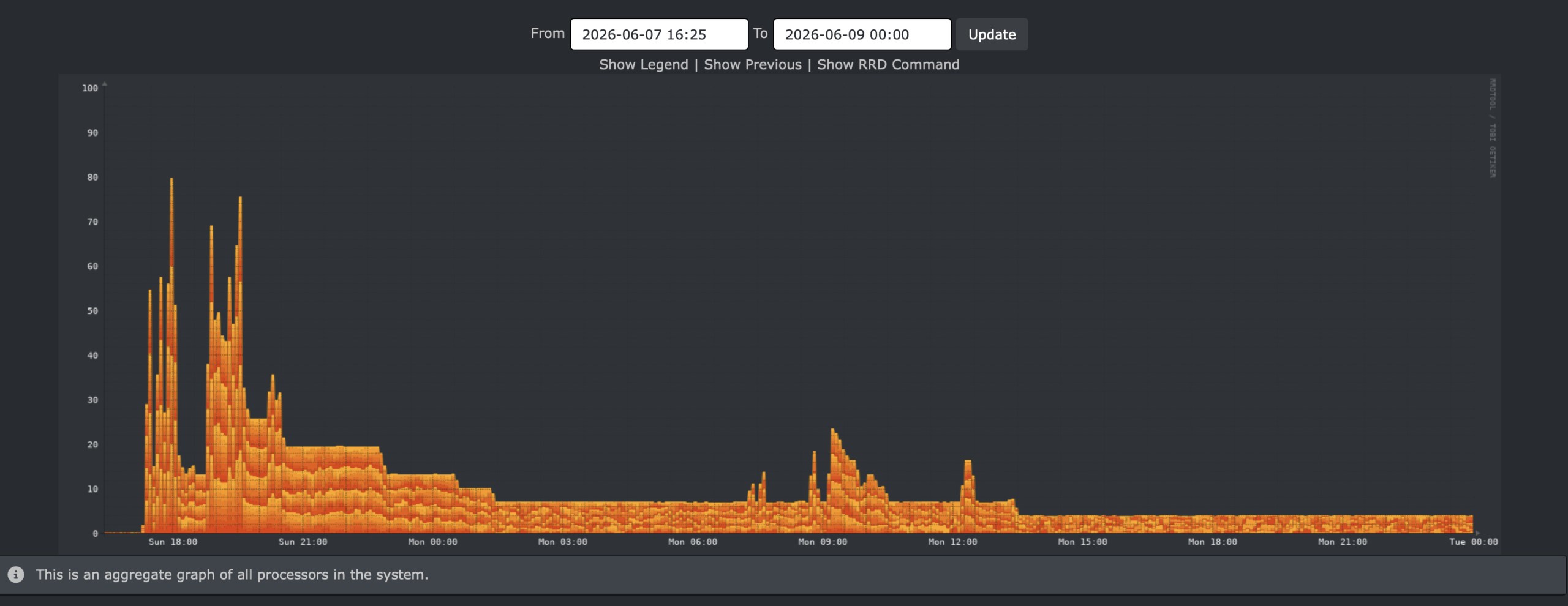
That’s two builds, pretty close to each other. Good enough for a starting point.
ifconfig bge0 -txcsum
Here, I did some testing on the NIC, but I feel that should not skew the results
Adding ALLOW_MAKE_JOBS*
For the fourth run, I added this to /usr/local/etc/poudriere.conf:
ALLOW_MAKE_JOBS=yes ALLOW_MAKE_JOBS_PACKAGES="pkg ccache py* llvm* mongodb* cmake binutils samba* gdb mysql*-server png graphviz gcc* sdocbook rust vaultwarden librenms ghc"
Started. See https://pkg02.int.unixathome.org//build.html?mastername=150amd64-default-primary&build=2026-06-09_12h26m11s
That run took only 05:43:24 – that’s only 20% of the previous time. Wow.
Here’s the graph, with some of the previous run showing.
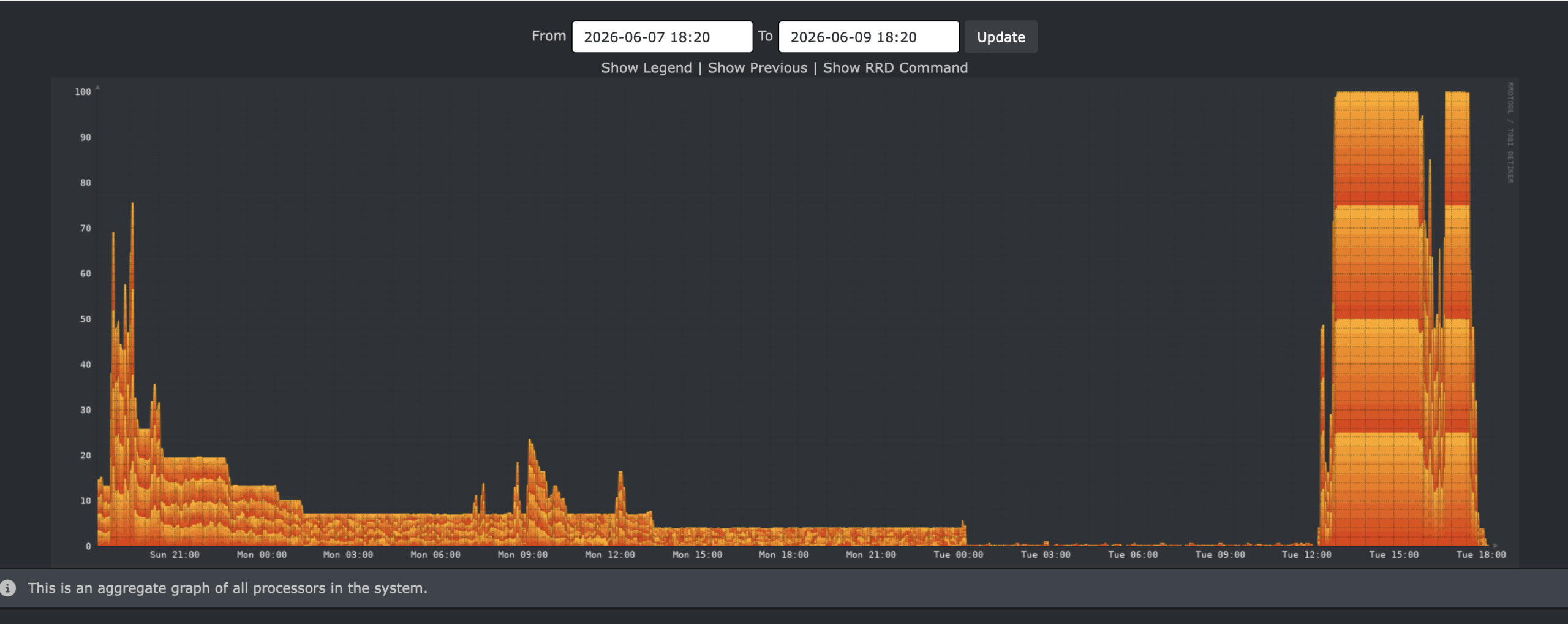
It is clear that much more CPU was used in parallel.
USE_TMPFS=”all”
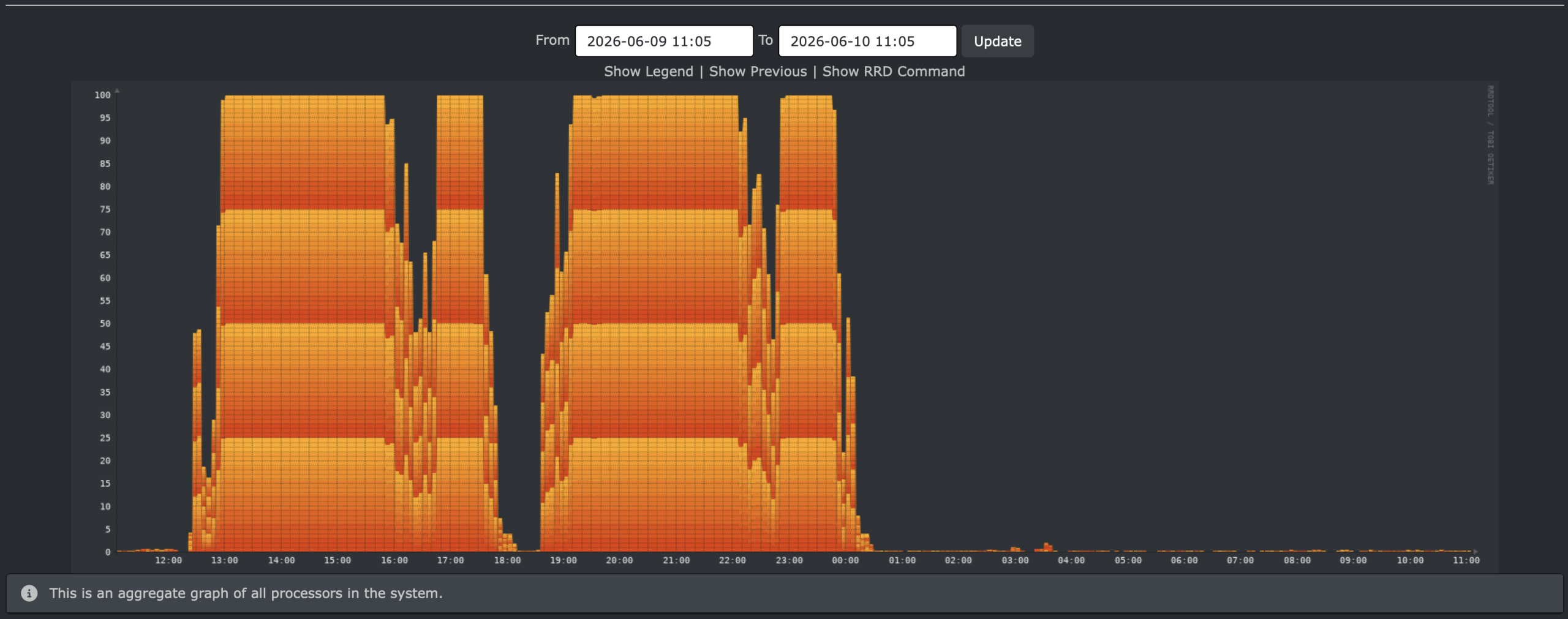
Previous runs have used USE_TMPFS=yes, now let’s use USE_TMPFS=”all” for the 5th run.
That run took 05:49:54 – definitely not as big of a time boost as I hoped.
The 4th (ALLOW_MAKE_JOBS) and 5th (USE_TMPFS=”all”) builds are shown here:
6th build
For my 6th build, I expect no changes to the build times. The changes to /usr/local/etc/poudriere.conf are:
- USE_PORTLINT=YES (was NO)
- FREEBSD_HOST=_PROTO_://_CHANGE_THIS_ has been removed (defaults to ftp://ftp.freebsd.org)
- USE_TMPFS=all (was USE_TMPFS=”all”)
- URL_BASE=https://pkg02.int.unixathome.org (trailing / was removed – that change was done after the build started)
Full file:
[19:02 pkg02 dvl /usr/local/etc] % cat poudriere.conf ALLOW_MAKE_JOBS=yes ALLOW_MAKE_JOBS_PACKAGES="pkg ccache py* llvm* mongodb* cmake binutils samba* gdb mysql*-server png graphviz gcc* sdocbook rust vaultwarden librenms ghc" BASEFS=/usr/local/poudriere DISTFILES_CACHE=/usr/ports/distfiles RESOLV_CONF=/etc/resolv.conf URL_BASE=https://pkg02.int.unixathome.org USE_PORTLINT=YES USE_TMPFS=all ZPOOL=data01
The run log is here.
The graph:
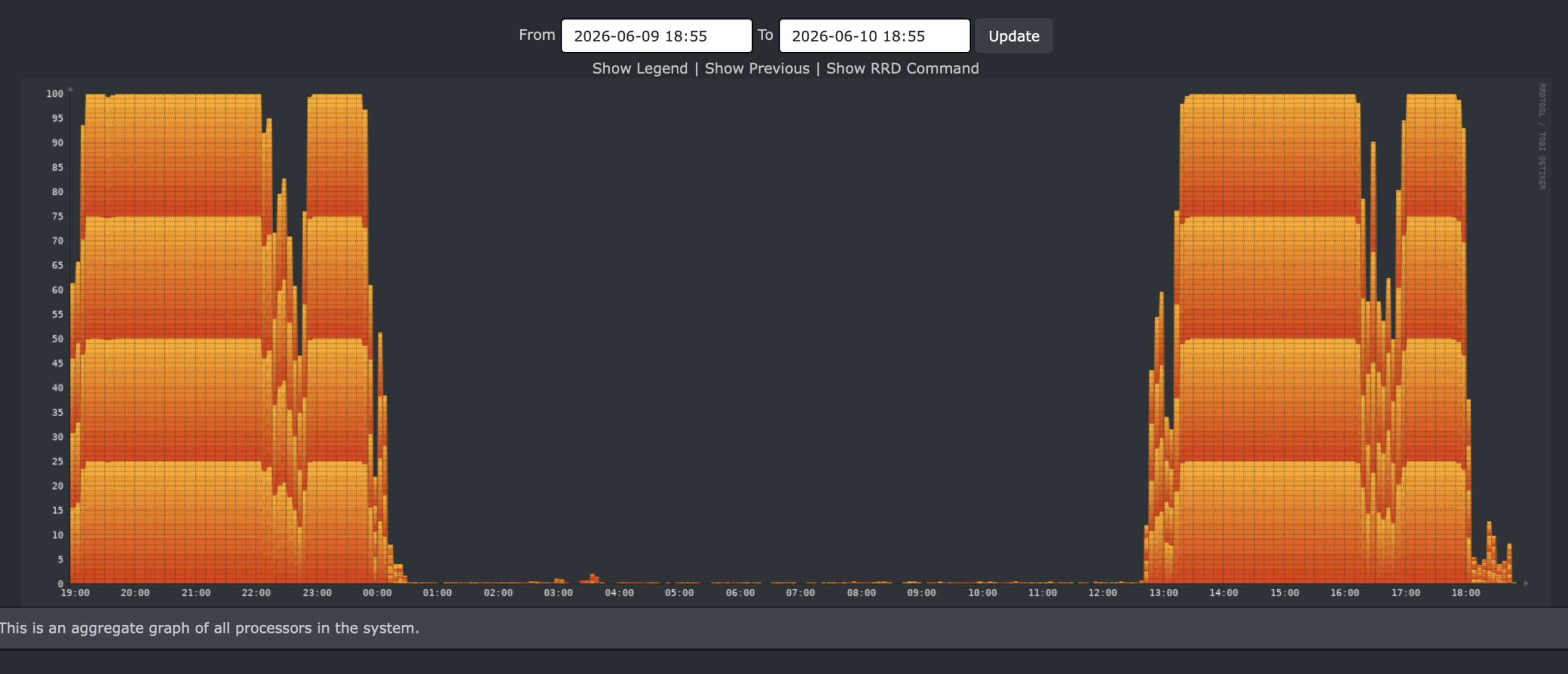
That took 05:59:34 – still in the same ball park.
My next change, go to SSDs.
SSD
I created a new jail, by copying the old jail, both /jails and the data it uses. It looks like this:
[13:48 pkg02ssd dvl ~] % zfs list NAME USED AVAIL REFER MOUNTPOINT zroot 20.6G 402G 96K /zroot zroot/poudriere 13.7G 402G 120K /usr/local/poudriere zroot/poudriere/data 4.25G 402G 128K /usr/local/poudriere/data zroot/poudriere/data/.m 160K 402G 96K /usr/local/poudriere/data/.m zroot/poudriere/data/cache 15.4M 402G 1.19M /usr/local/poudriere/data/cache zroot/poudriere/data/images 96K 402G 96K /usr/local/poudriere/data/images zroot/poudriere/data/logs 301M 402G 299M /usr/local/poudriere/data/logs zroot/poudriere/data/packages 3.94G 402G 3.94G /usr/local/poudriere/data/packages zroot/poudriere/data/wrkdirs 96K 402G 96K /usr/local/poudriere/data/wrkdirs zroot/poudriere/distfiles 6.91G 402G 6.91G /usr/local/poudriere/distfiles zroot/poudriere/jails 1.50G 402G 96K /usr/local/poudriere/jails zroot/poudriere/jails/150amd64 1.50G 402G 1.50G /usr/local/poudriere/jails/150amd64 zroot/poudriere/ports 1.02G 402G 96K /usr/local/poudriere/ports zroot/poudriere/ports/default 1.02G 402G 1.02G /usr/local/poudriere/ports/default
The copying was accomplished via:
root@r7425-01:~ # syncoid -r data01/poudriere zroot/poudriere
and
root@r7425-01:/usr/local/etc/jail.conf.d # syncoid -r data01/jails/pkg02 data01/jails/pkg02ssd
I used syncoid (from the sysutils/sanoid package) because it is easier on my head. One. Simple. Command. Done.
A build is underway now.
An aside: the mounts
Here are all the mounts I saw at 04:19:06 into the build. This is what I saw when I pressed CTL-T:
[150amd64-default-primary] [2026-06-11_13h45m59s] [parallel_build] Queued: 962 Built: 919 Failed: 8 Skipped: 10 Ignored: 1 Fetched: 0 Tobuild: 24 Time: 04:19:06 ID TOTAL ORIGIN PKGNAME PHASE PHASE TMPFS CPU% MEM% [01] 00:02:23 security/py-cryptography@py312 | py312-cryptography-48.0.0,1 build 00:01:01 2.47 GiB 62.5% 0.2% [02] 00:08:27 databases/mongodb70@default | mongodb70-7.0.34_1 build 00:06:32 7.36 GiB 2020.2% 5.3% [03] 00:13:31 devel/cargo-c | cargo-c-0.10.23 build 00:11:19 3.45 GiB 63.1% 0.8% [17] 03:50:59 lang/ghc | ghc-9.10.3_2 build 03:45:21 10.05 GiB 188.3% 0.6% [06] 00:13:31 security/vaultwarden | vaultwarden-1.36.0 build 00:08:53 4.58 GiB 68.3% 1.1% [04:19:11] Logs: /usr/local/poudriere/data/logs/bulk/150amd64-default-primary/2026-06-11_13h45m59s [04:19:11] WWW: https://pkg02.int.unixathome.org/build.html?mastername=150amd64-default-primary&build=2026-06-11_13h45m59s
And the mounts (tldr;skip):
[18:04 pkg02ssd dvl ~] % mount data01/jails/pkg02ssd on / (zfs, local, nfsv4acls) devfs on /dev (devfs) zroot/poudriere on /usr/local/poudriere (zfs, local, noatime, nfsv4acls) zroot/poudriere/jails on /usr/local/poudriere/jails (zfs, local, noatime, nfsv4acls) zroot/poudriere/ports on /usr/local/poudriere/ports (zfs, local, noatime, nfsv4acls) zroot/poudriere/data on /usr/local/poudriere/data (zfs, local, noatime, nfsv4acls) zroot/poudriere/distfiles on /usr/local/poudriere/distfiles (zfs, local, noatime, nfsv4acls) zroot/poudriere/ports/default on /usr/local/poudriere/ports/default (zfs, local, noatime, nfsv4acls) zroot/poudriere/jails/150amd64 on /usr/local/poudriere/jails/150amd64 (zfs, local, noatime, nfsv4acls) zroot/poudriere/data/.m on /usr/local/poudriere/data/.m (zfs, local, noatime, nfsv4acls) zroot/poudriere/data/cache on /usr/local/poudriere/data/cache (zfs, local, noatime, nfsv4acls) zroot/poudriere/data/wrkdirs on /usr/local/poudriere/data/wrkdirs (zfs, local, noatime, nfsv4acls) zroot/poudriere/data/images on /usr/local/poudriere/data/images (zfs, local, noatime, nfsv4acls) zroot/poudriere/data/logs on /usr/local/poudriere/data/logs (zfs, local, noatime, nfsv4acls) zroot/poudriere/data/packages on /usr/local/poudriere/data/packages (zfs, local, noatime, nfsv4acls) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/ref (tmpfs, local) /usr/local/poudriere/jails/150amd64/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue (nullfs, local, read-only) /usr/local/poudriere/jails/150amd64/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/jails/150amd64/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share (nullfs, local, read-only) /usr/local/poudriere/jails/150amd64/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests (nullfs, local, read-only) /usr/local/poudriere/jails/150amd64/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/ref/dev (devfs) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/ref/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/ref/compat/linux/proc (linprocfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/ref/.p (tmpfs, local) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/ref/packages (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/ref/distfiles (nullfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/01 (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/01/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/01/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/01/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/01/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/01/usr/src (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/01/dev (devfs) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/01/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/01/compat/linux/proc (linprocfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/01/.p (tmpfs, local) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/01/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/01/packages (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/01/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/01/var/db/ports (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/02 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/03 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/04 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/05 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/06 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/07 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/08 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/09 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/10 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/11 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/12 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/13 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/14 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/15 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/16 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/17 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/18 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/19 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/20 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/21 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/22 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/23 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/25 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/24 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/26 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/27 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/28 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/29 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/30 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/32 (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/31 (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/05/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/11/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/05/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/11/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/11/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/05/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/11/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/05/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/11/usr/src (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/11/dev (devfs) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/05/usr/src (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/05/dev (devfs) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/11/proc (procfs, local) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/05/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/11/compat/linux/proc (linprocfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/05/compat/linux/proc (linprocfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/11/.p (tmpfs, local) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/11/usr/ports (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/05/.p (tmpfs, local) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/11/packages (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/05/usr/ports (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/11/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/02/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/02/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/05/packages (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/02/usr/share (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/05/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/11/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/02/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/20/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/05/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/20/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/02/usr/src (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/02/dev (devfs) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/20/usr/share (nullfs, local, read-only) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/02/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/02/compat/linux/proc (linprocfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/20/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/20/usr/src (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/02/.p (tmpfs, local) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/20/dev (devfs) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/02/usr/ports (nullfs, local, read-only) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/20/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/20/compat/linux/proc (linprocfs, local) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/02/packages (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/02/distfiles (nullfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/20/.p (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/02/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/20/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/20/packages (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/18/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/23/rescue (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/20/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/18/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/23/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/20/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/18/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/26/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/23/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/23/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/26/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/18/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/26/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/23/usr/src (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/18/usr/src (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/26/usr/tests (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/18/dev (devfs) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/23/dev (devfs) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/26/usr/src (nullfs, local, read-only) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/23/proc (procfs, local) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/18/proc (procfs, local) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/26/dev (devfs) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/23/compat/linux/proc (linprocfs, local) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/26/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/26/compat/linux/proc (linprocfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/18/compat/linux/proc (linprocfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/23/.p (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/26/.p (tmpfs, local) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/23/usr/ports (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/18/.p (tmpfs, local) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/26/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/26/packages (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/23/packages (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/18/usr/ports (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/26/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/26/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/18/packages (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/23/distfiles (nullfs, local) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/18/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/23/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/18/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/06/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/06/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/06/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/06/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/29/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/06/usr/src (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/29/usr/lib32 (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/06/dev (devfs) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/29/usr/share (nullfs, local, read-only) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/06/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/06/compat/linux/proc (linprocfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/29/usr/tests (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/06/.p (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/29/usr/src (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/06/usr/ports (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/29/dev (devfs) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/29/proc (procfs, local) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/06/packages (nullfs, local, read-only) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/29/compat/linux/proc (linprocfs, local) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/06/distfiles (nullfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/29/.p (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/06/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/16/rescue (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/29/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/10/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/16/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/29/packages (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/10/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/16/usr/share (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/29/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/10/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/29/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/16/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/10/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/16/usr/src (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/10/usr/src (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/16/dev (devfs) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/10/dev (devfs) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/16/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/16/compat/linux/proc (linprocfs, local) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/10/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/10/compat/linux/proc (linprocfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/16/.p (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/10/.p (tmpfs, local) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/16/usr/ports (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/10/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/16/packages (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/10/packages (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/16/distfiles (nullfs, local) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/10/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/16/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/10/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/27/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/27/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/27/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/27/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/13/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/27/usr/src (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/13/usr/lib32 (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/27/dev (devfs) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/27/proc (procfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/13/usr/share (nullfs, local, read-only) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/27/compat/linux/proc (linprocfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/13/usr/tests (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/27/.p (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/13/usr/src (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/27/usr/ports (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/13/dev (devfs) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/09/rescue (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/27/packages (nullfs, local, read-only) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/13/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/13/compat/linux/proc (linprocfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/09/usr/lib32 (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/27/distfiles (nullfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/13/.p (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/27/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/09/usr/share (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/13/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/09/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/08/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/03/rescue (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/13/packages (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/09/usr/src (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/08/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/03/usr/lib32 (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/09/dev (devfs) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/13/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/08/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/03/usr/share (nullfs, local, read-only) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/09/proc (procfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/13/var/db/ports (nullfs, local, read-only) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/09/compat/linux/proc (linprocfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/08/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/03/usr/tests (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/09/.p (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/08/usr/src (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/03/usr/src (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/09/usr/ports (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/08/dev (devfs) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/03/dev (devfs) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/08/proc (procfs, local) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/03/proc (procfs, local) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/09/packages (nullfs, local, read-only) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/08/compat/linux/proc (linprocfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/03/compat/linux/proc (linprocfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/08/.p (tmpfs, local) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/09/distfiles (nullfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/03/.p (tmpfs, local) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/08/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/09/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/03/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/08/packages (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/21/rescue (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/03/packages (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/08/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/21/usr/lib32 (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/03/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/08/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/21/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/03/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/21/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/21/usr/src (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/21/dev (devfs) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/19/rescue (nullfs, local, read-only) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/21/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/21/compat/linux/proc (linprocfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/19/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/19/usr/share (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/21/.p (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/19/usr/tests (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/21/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/19/usr/src (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/21/packages (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/19/dev (devfs) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/19/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/19/compat/linux/proc (linprocfs, local) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/21/distfiles (nullfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/19/.p (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/21/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/19/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/19/packages (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/19/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/19/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/15/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/15/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/15/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/15/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/15/usr/src (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/15/dev (devfs) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/15/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/15/compat/linux/proc (linprocfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/15/.p (tmpfs, local) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/15/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/15/packages (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/15/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/15/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/17/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/17/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/17/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/04/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/17/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/04/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/17/usr/src (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/04/usr/share (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/17/dev (devfs) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/04/usr/tests (nullfs, local, read-only) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/17/proc (procfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/04/usr/src (nullfs, local, read-only) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/17/compat/linux/proc (linprocfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/24/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/07/rescue (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/04/dev (devfs) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/24/usr/lib32 (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/17/.p (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/07/usr/lib32 (nullfs, local, read-only) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/04/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/04/compat/linux/proc (linprocfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/24/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/07/usr/share (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/17/usr/ports (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/04/.p (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/07/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/24/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/17/packages (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/25/rescue (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/04/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/07/usr/src (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/24/usr/src (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/07/dev (devfs) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/17/distfiles (nullfs, local) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/04/packages (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/25/usr/lib32 (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/24/dev (devfs) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/07/proc (procfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/17/var/db/ports (nullfs, local, read-only) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/07/compat/linux/proc (linprocfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/14/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/25/usr/share (nullfs, local, read-only) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/24/proc (procfs, local) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/04/distfiles (nullfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/07/.p (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/14/usr/lib32 (nullfs, local, read-only) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/24/compat/linux/proc (linprocfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/25/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/04/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/07/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/14/usr/share (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/24/.p (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/25/usr/src (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/14/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/07/packages (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/25/dev (devfs) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/24/usr/ports (nullfs, local, read-only) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/25/proc (procfs, local) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/07/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/14/usr/src (nullfs, local, read-only) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/25/compat/linux/proc (linprocfs, local) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/24/packages (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/14/dev (devfs) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/14/proc (procfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/07/var/db/ports (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/25/.p (tmpfs, local) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/24/distfiles (nullfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/14/compat/linux/proc (linprocfs, local) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/25/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/24/var/db/ports (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/14/.p (tmpfs, local) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/25/packages (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/14/usr/ports (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/25/distfiles (nullfs, local) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/14/packages (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/25/var/db/ports (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/14/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/14/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/28/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/12/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/28/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/12/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/28/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/22/rescue (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/12/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/28/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/22/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/12/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/28/usr/src (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/22/usr/share (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/28/dev (devfs) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/12/usr/src (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/22/usr/tests (nullfs, local, read-only) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/28/proc (procfs, local) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/12/dev (devfs) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/28/compat/linux/proc (linprocfs, local) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/12/proc (procfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/22/usr/src (nullfs, local, read-only) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/12/compat/linux/proc (linprocfs, local) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/22/dev (devfs) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/28/.p (tmpfs, local) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/22/proc (procfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/12/.p (tmpfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/22/compat/linux/proc (linprocfs, local) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/28/usr/ports (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/12/usr/ports (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/22/.p (tmpfs, local) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/28/packages (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/12/packages (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/22/usr/ports (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/28/distfiles (nullfs, local) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/12/distfiles (nullfs, local) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/22/packages (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/28/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/32/rescue (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/22/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/12/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/32/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/22/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/32/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/32/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/32/usr/src (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/32/dev (devfs) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/32/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/32/compat/linux/proc (linprocfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/32/.p (tmpfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/31/rescue (nullfs, local, read-only) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/32/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/31/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/32/packages (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/31/usr/share (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/32/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/31/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/31/usr/src (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/32/var/db/ports (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/31/dev (devfs) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/31/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/31/compat/linux/proc (linprocfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/31/.p (tmpfs, local) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/31/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/31/packages (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/rescue on /usr/local/poudriere/data/.m/150amd64-default-primary/30/rescue (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/31/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/lib32 on /usr/local/poudriere/data/.m/150amd64-default-primary/30/usr/lib32 (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/31/var/db/ports (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/share on /usr/local/poudriere/data/.m/150amd64-default-primary/30/usr/share (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/tests on /usr/local/poudriere/data/.m/150amd64-default-primary/30/usr/tests (nullfs, local, read-only) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/usr/src on /usr/local/poudriere/data/.m/150amd64-default-primary/30/usr/src (nullfs, local, read-only) devfs on /usr/local/poudriere/data/.m/150amd64-default-primary/30/dev (devfs) procfs on /usr/local/poudriere/data/.m/150amd64-default-primary/30/proc (procfs, local) linprocfs on /usr/local/poudriere/data/.m/150amd64-default-primary/30/compat/linux/proc (linprocfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/30/.p (tmpfs, local) /usr/local/poudriere/ports/default on /usr/local/poudriere/data/.m/150amd64-default-primary/30/usr/ports (nullfs, local, read-only) /usr/local/poudriere/data/packages/150amd64-default-primary/.building on /usr/local/poudriere/data/.m/150amd64-default-primary/30/packages (nullfs, local, read-only) /usr/ports/distfiles on /usr/local/poudriere/data/.m/150amd64-default-primary/30/distfiles (nullfs, local) /usr/local/poudriere/data/.m/150amd64-default-primary/ref/var/db/ports on /usr/local/poudriere/data/.m/150amd64-default-primary/30/var/db/ports (nullfs, local, read-only) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/17/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/14/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/13/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/18/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/21/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/29/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/31/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/19/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/28/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/32/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/22/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/27/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/24/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/20/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/23/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/26/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/30/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/25/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/15/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/16/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/03/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/09/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/11/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/10/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/08/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/06/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/04/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/07/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/12/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/05/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/02/usr/local (tmpfs, local) tmpfs on /usr/local/poudriere/data/.m/150amd64-default-primary/01/usr/local (tmpfs, local)
Is this using multiple jobs?
Here’s what I see poudriere doing:
[18:06 pkg02ssd dvl ~] % ps auwwx | grep 'sh: poudriere' root 17508 0.1 0.0 16860 4608 5 D+J 13:46 1:09.84 sh: poudriere[150amd64-default-primary]: html_json_main (sh) root 67814 0.1 0.0 16860 5044 5 SJ 18:06 0:00.04 sh: poudriere[150amd64-default-primary][01]: build_pkg (py312-aioquic-1.3.0_1) (sh) dvl 68908 0.0 0.0 14164 2676 0 S+J 18:07 0:00.00 grep sh: poudriere root 13418 0.0 0.0 16860 5076 5 IJ 17:53 0:00.00 sh: poudriere[150amd64-default-primary][03]: build_pkg (cargo-c-0.10.23) (sh) root 22436 0.0 0.0 16860 5080 5 IJ 17:51 0:00.30 sh: poudriere[150amd64-default-primary][03]: build_pkg (cargo-c-0.10.23) (sh) root 22491 0.0 0.0 16860 5088 5 IJ 17:51 0:00.26 sh: poudriere[150amd64-default-primary][06]: build_pkg (vaultwarden-1.36.0) (sh) root 31909 0.0 0.0 16860 4988 5 I+J 13:46 0:04.23 sh: poudriere[150amd64-default-primary]: pkg_cacher_main (sh) root 39151 0.0 0.0 16860 5084 5 IJ 17:56 0:00.00 sh: poudriere[150amd64-default-primary][06]: build_pkg (vaultwarden-1.36.0) (sh) root 40630 0.0 0.0 16860 5032 5 IJ 17:56 0:00.05 sh: poudriere[150amd64-default-primary][02]: build_pkg (mongodb70-7.0.34_1) (sh) root 48052 0.0 0.0 16860 5028 5 IJ 17:58 0:00.00 sh: poudriere[150amd64-default-primary][02]: build_pkg (mongodb70-7.0.34_1) (sh) root 59441 0.0 0.0 16860 5028 5 IJ 14:19 0:00.00 sh: poudriere[150amd64-default-primary][17]: build_pkg (ghc-9.10.3_2) (sh) root 63410 0.0 0.0 16860 5044 5 SJ 18:05 0:00.05 sh: poudriere[150amd64-default-primary][05]: build_pkg (py312-ansible-core-2.19.9) (sh) root 67823 0.0 0.0 16860 5044 5 SJ 18:06 0:00.04 sh: poudriere[150amd64-default-primary][04]: build_pkg (py312-twisted-25.5.0) (sh) root 68250 0.0 0.0 16860 5040 5 SJ 18:06 0:00.00 sh: poudriere[150amd64-default-primary][05]: build_pkg (py312-ansible-core-2.19.9) (sh) root 68853 0.0 0.0 16860 5040 5 SJ 18:07 0:00.00 sh: poudriere[150amd64-default-primary][04]: build_pkg (py312-twisted-25.5.0) (sh) root 68902 0.0 0.0 16860 4608 5 RV+J 18:07 0:00.00 sh: poudriere[150amd64-default-primary]: html_json_main (sh) root 99762 0.0 0.0 16860 5032 5 IJ 14:14 0:00.06 sh: poudriere[150amd64-default-primary][17]: build_pkg (ghc-9.10.3_2) (sh)
Vital stats
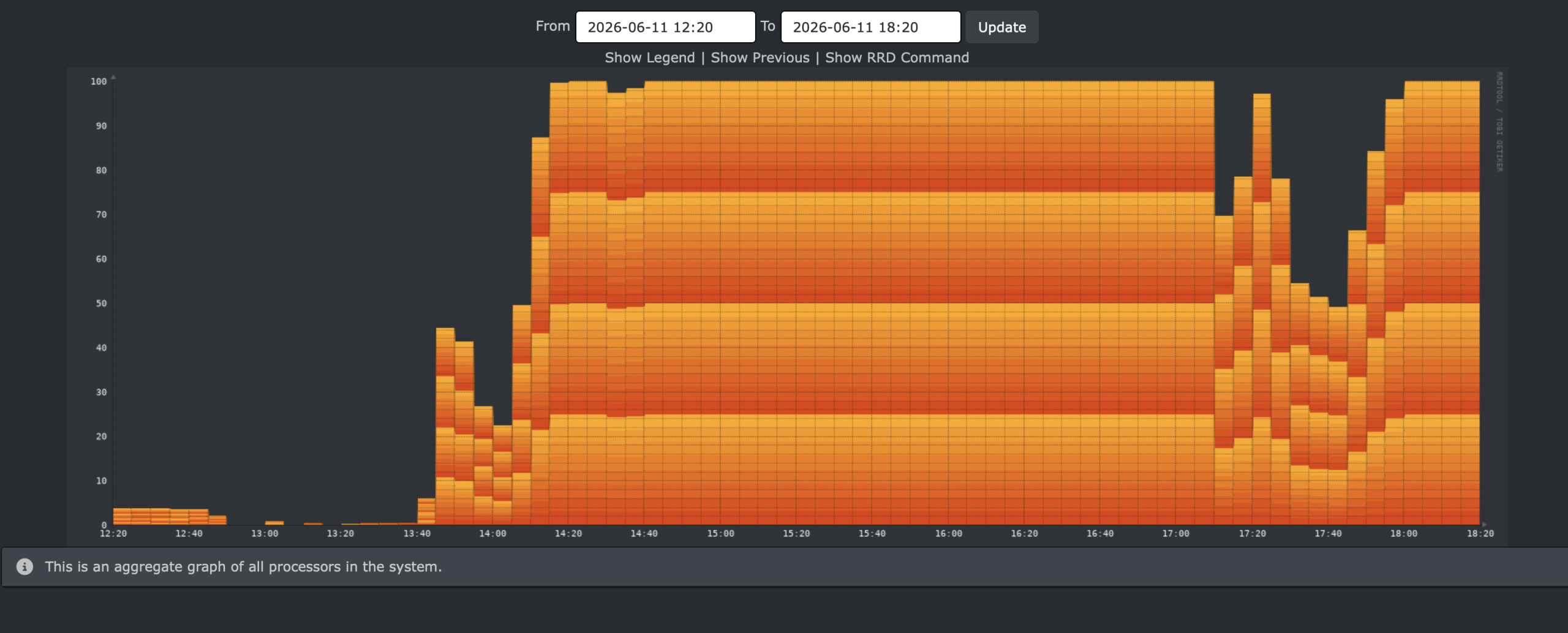
I suspect this is CPU bound.
This is diskio:
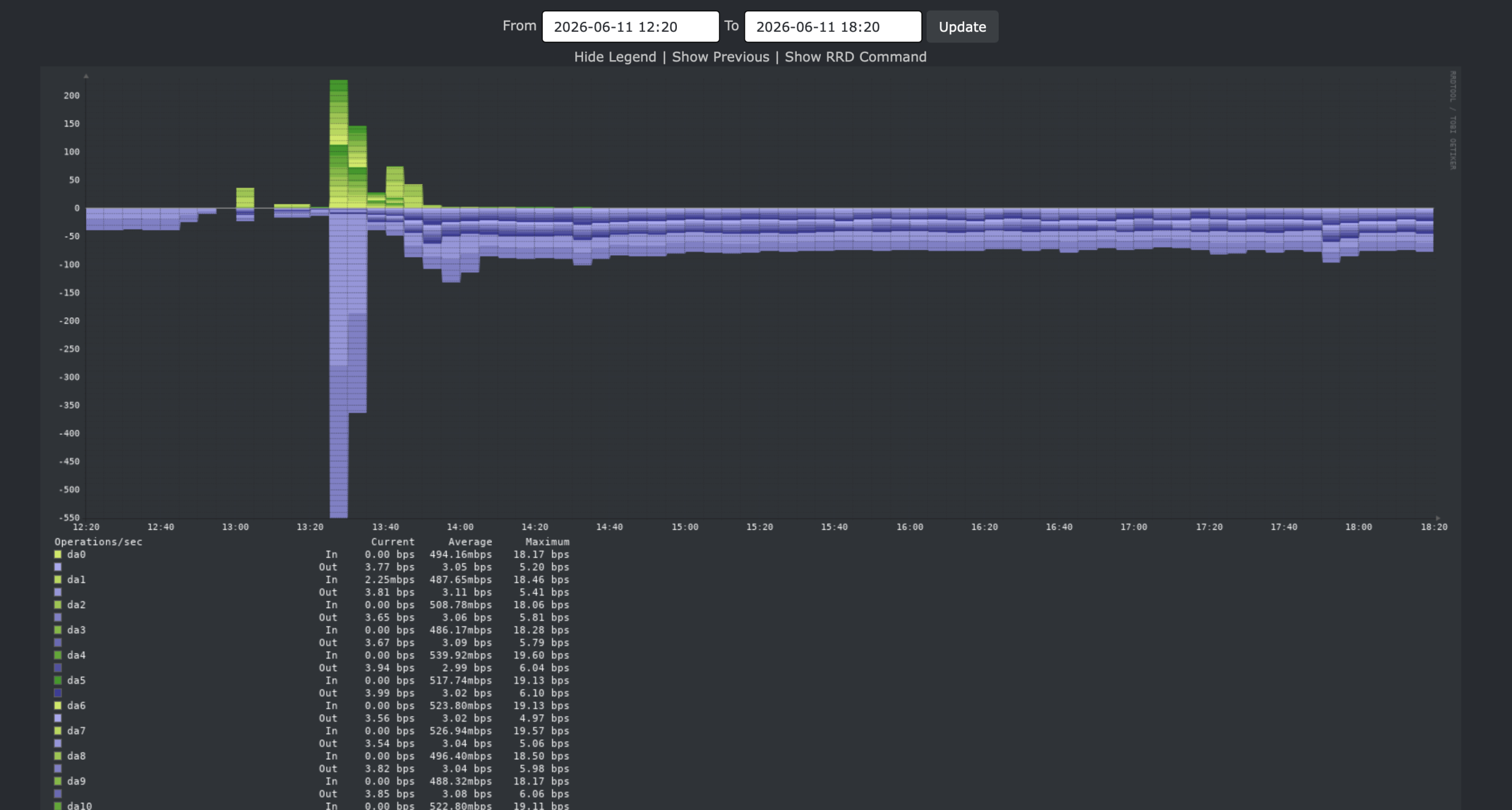
This is CPU usage:
This is memory usage:
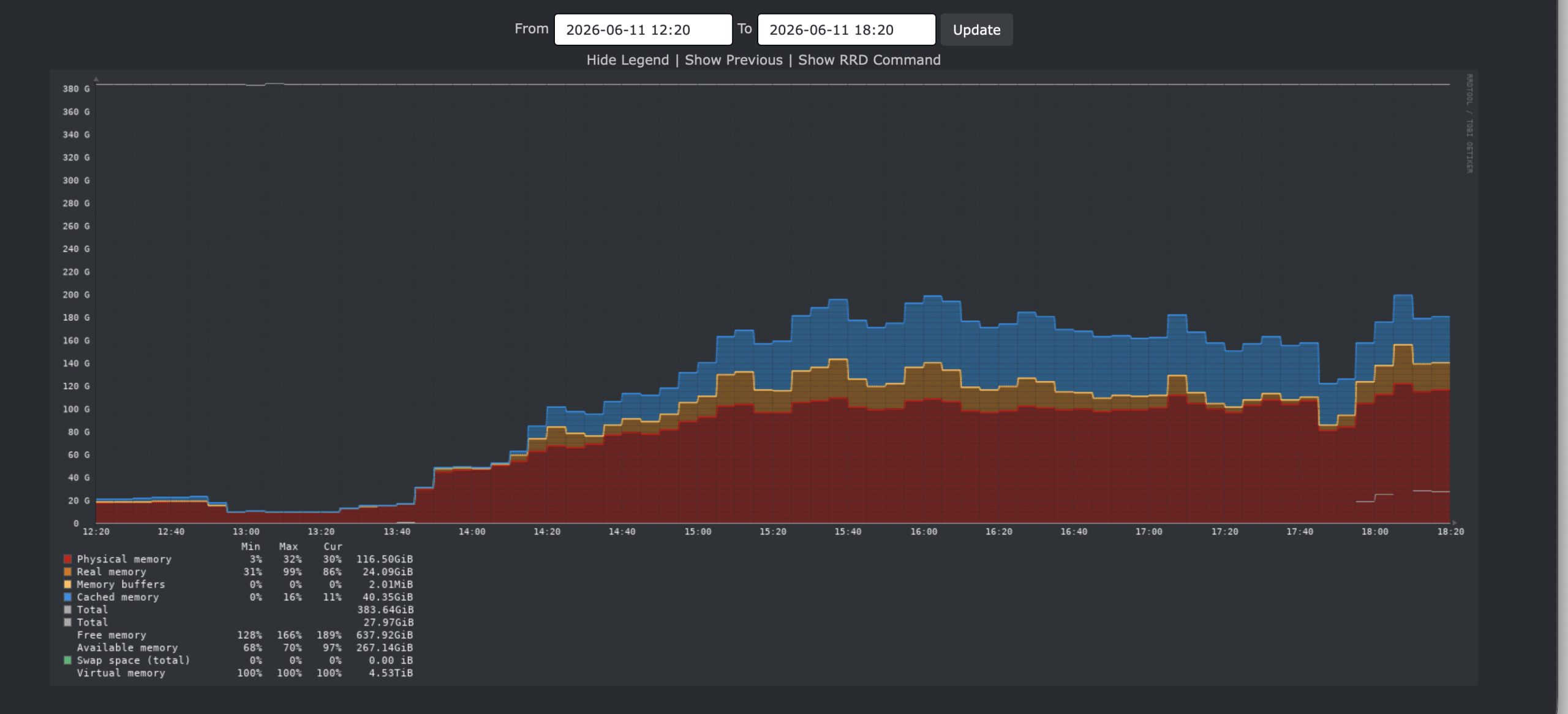
It appears we are mostly CPU bound here….
Finished. Total time was 05:44:47
Not much faster than the HDD – clearly, everything says this is CPU bound.
Comparison to pkg01
Let’s do a test build over on pkg01, and see.
The link for this build is publicly accessible.
ase server
That took 03:52:31
Here’s the graphs. One major difference: this host is multi-use. It hosts four FreshPorts instances (dvl, dev, test, and stage) and their database server. In all, it runs 38 jails, including pkg01 on which this last test is run.
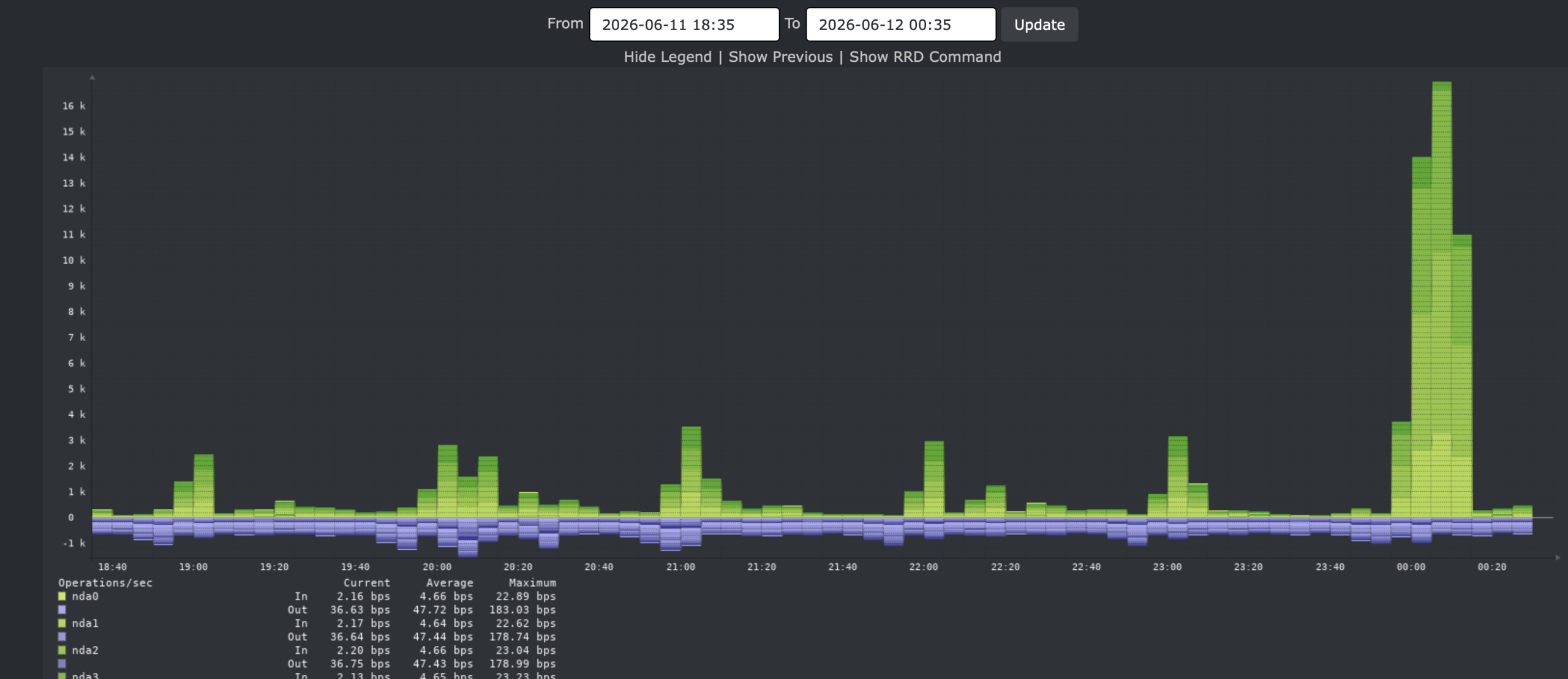
Disk IO:
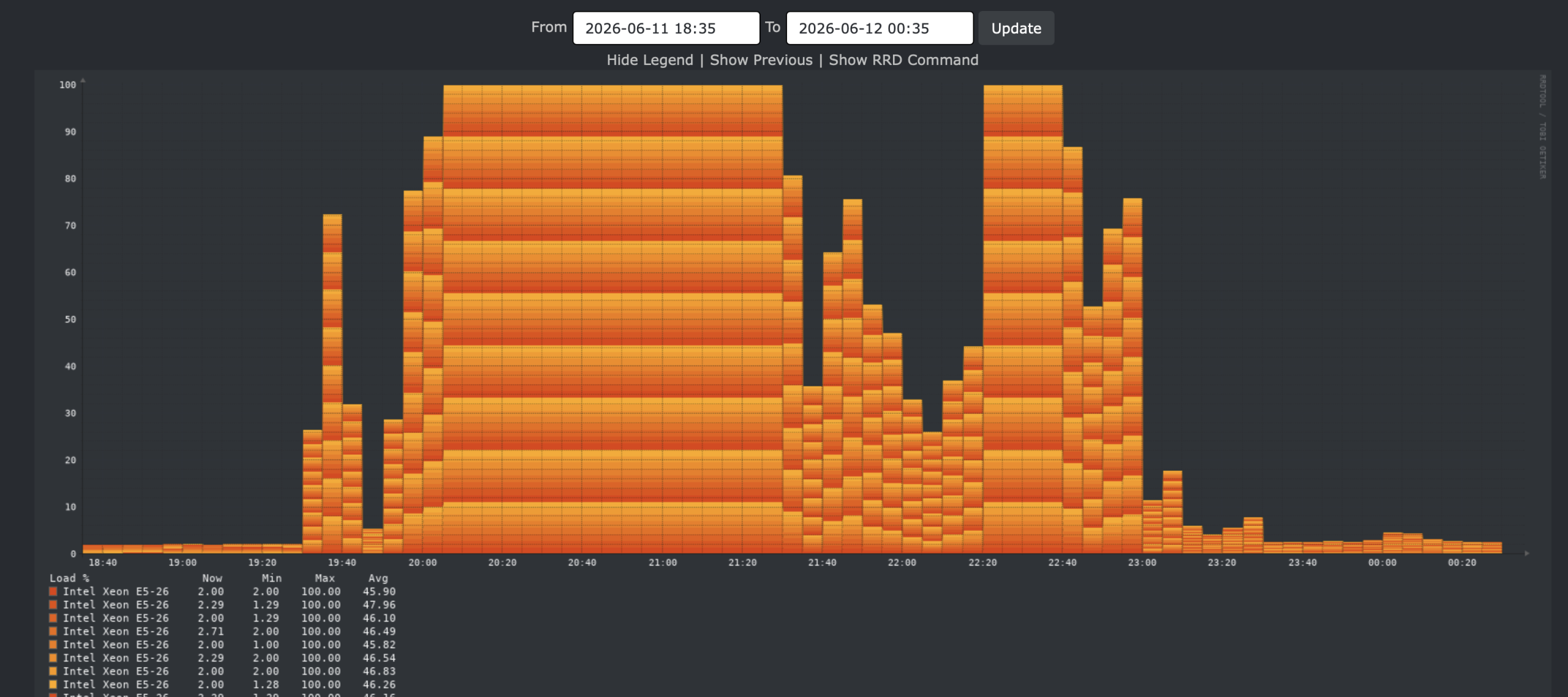
CPU:
Memory:
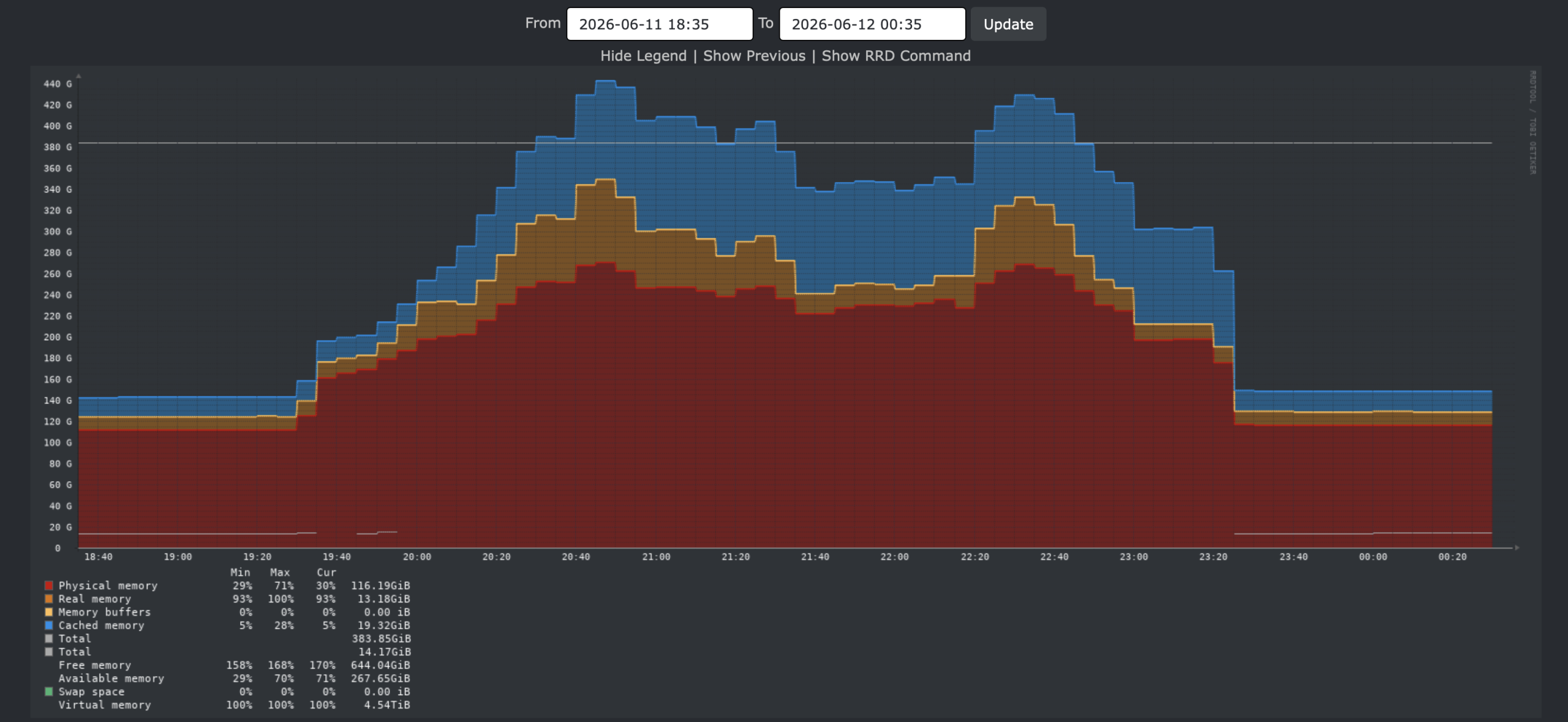
Again, it is CPU bound. It’s clearly the number of CPUs which reduce the build time.
Conclusion
I don’t see any reason to move my poudriere server (pkg01) from r730-01 to r7425-01. Things shall remain where they are, for building packges.


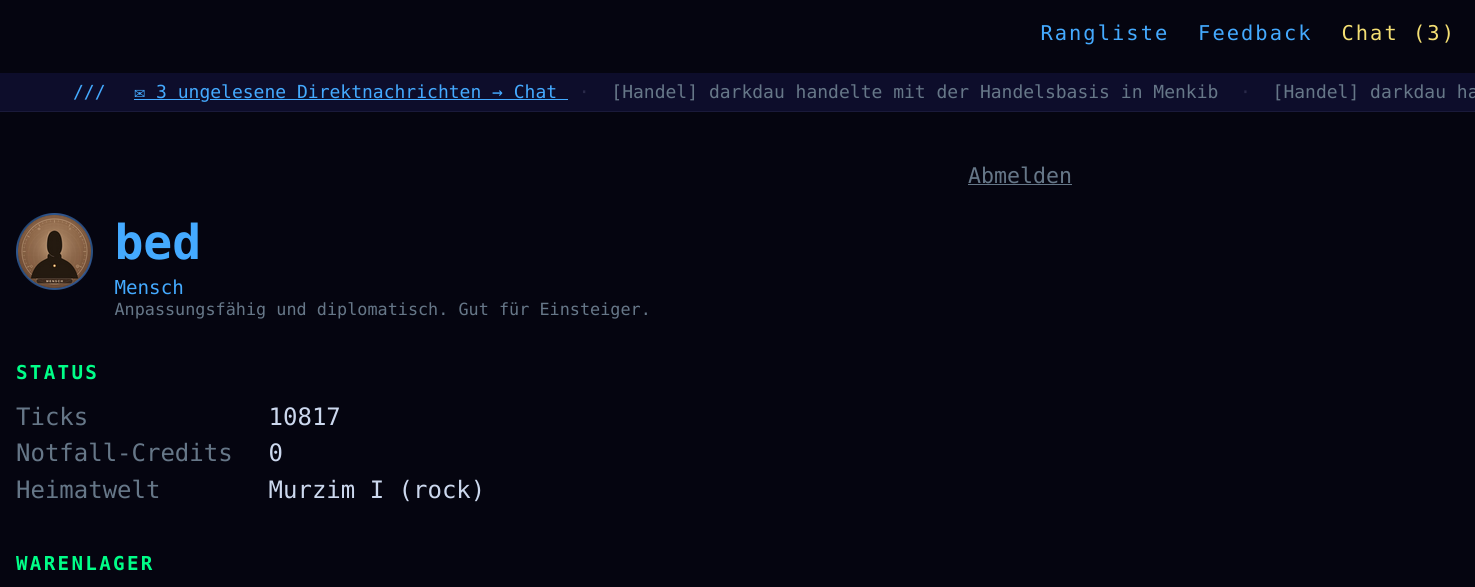
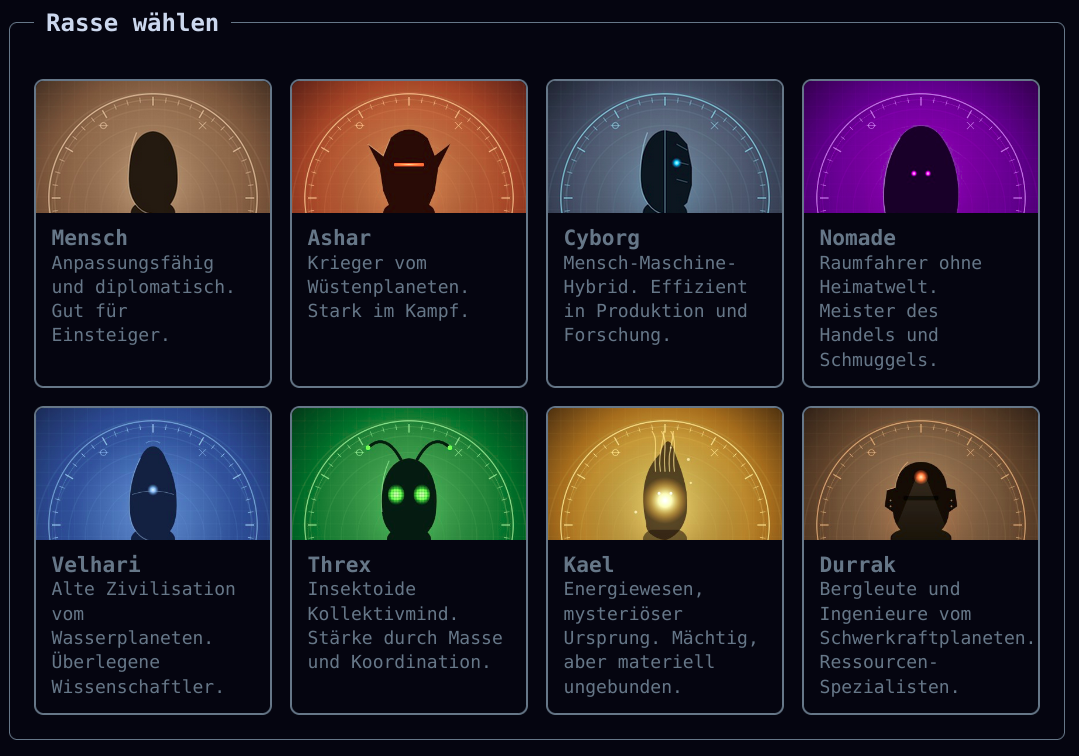
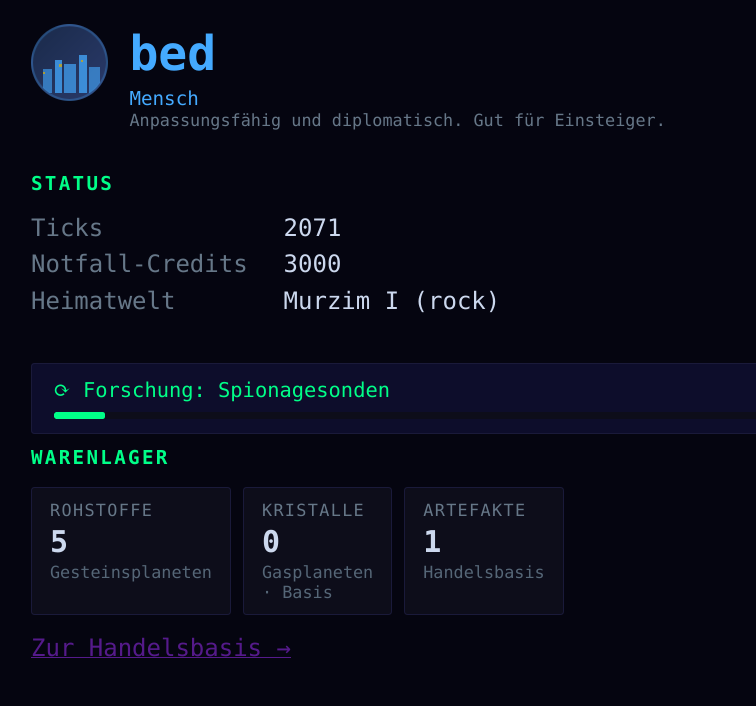
 Das Spiel gibt an bestimmten Stellen Hinweise, wenn etwas noch nicht stimmt. Wer zum Beispiel einen Gesteinsplaneten besiedelt hat, aber noch keinen Bergbau erforscht, bekommt den Hinweis direkt im Dashboard. Kein stilles Warten, keine Raterei warum die Rohstoffe nicht wachsen. Der Tipp verschwindet, sobald die passende Forschung gestartet ist.
Das Spiel gibt an bestimmten Stellen Hinweise, wenn etwas noch nicht stimmt. Wer zum Beispiel einen Gesteinsplaneten besiedelt hat, aber noch keinen Bergbau erforscht, bekommt den Hinweis direkt im Dashboard. Kein stilles Warten, keine Raterei warum die Rohstoffe nicht wachsen. Der Tipp verschwindet, sobald die passende Forschung gestartet ist.