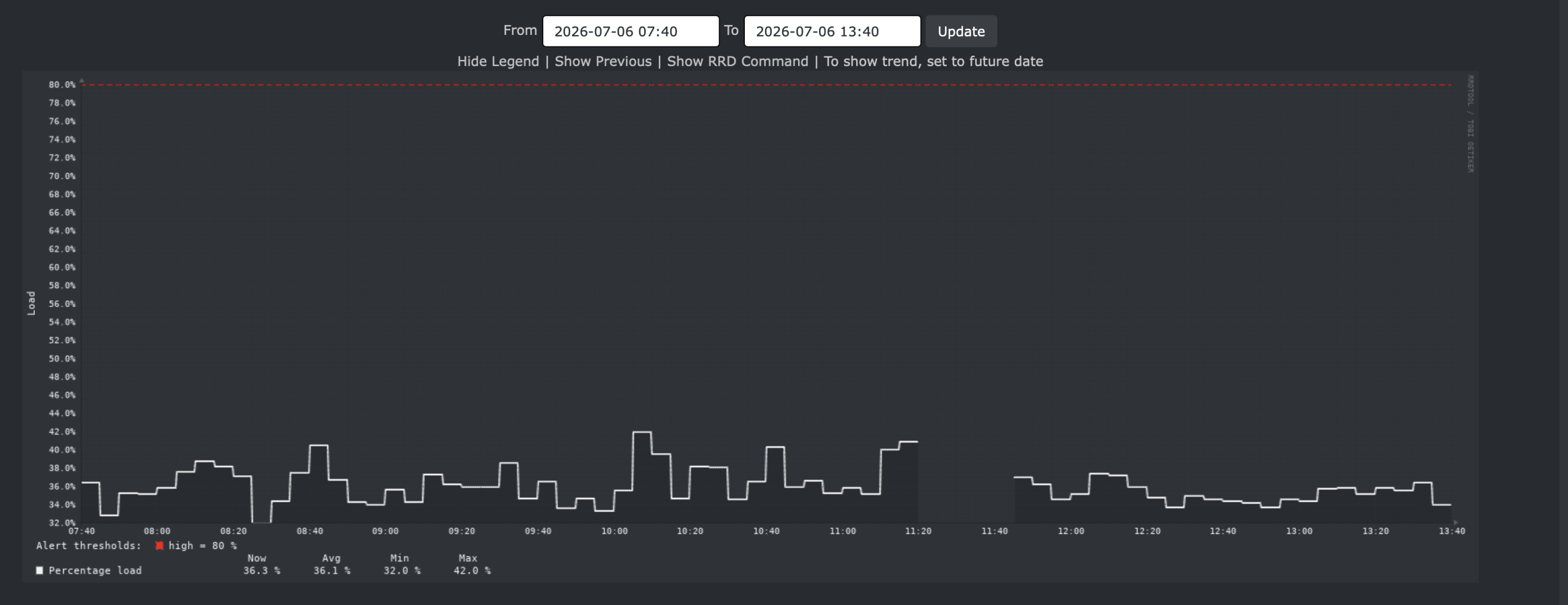
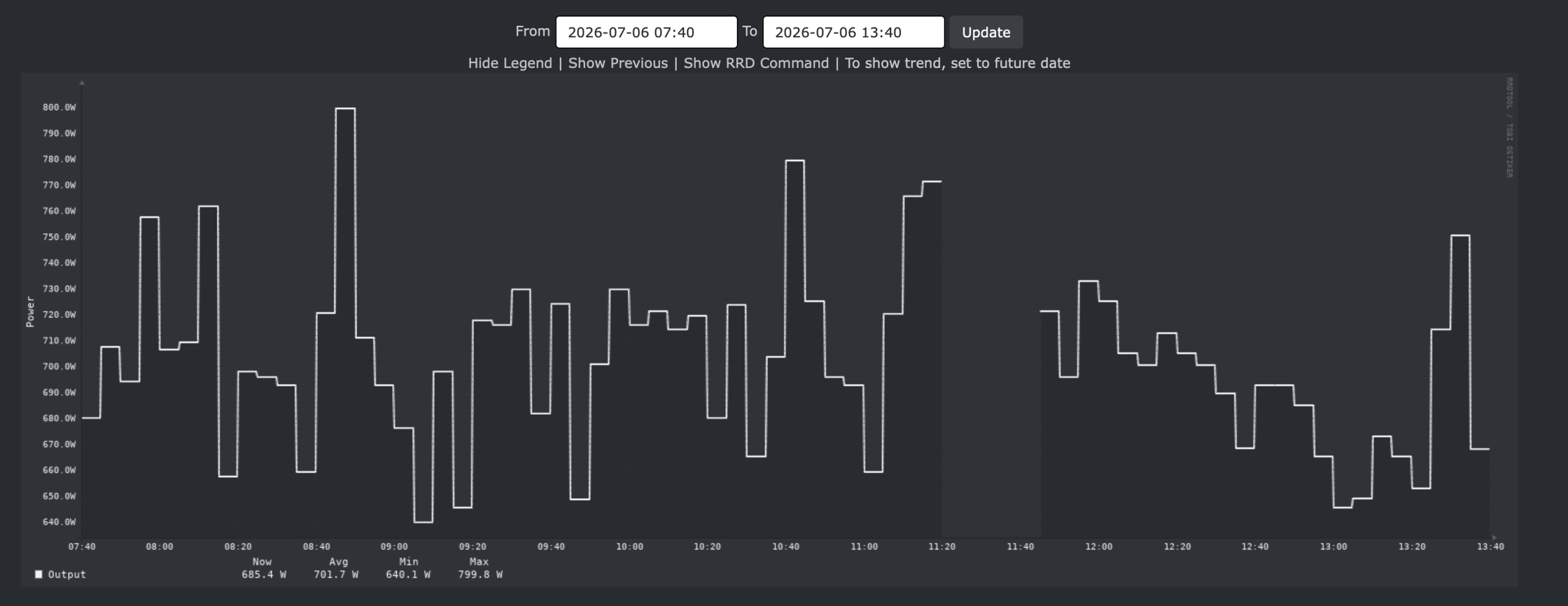
The Valuable News weekly series is dedicated to provide summary about news, articles and other interesting stuff mostly but not always related to the UNIX/BSD/Linux systems. Whenever I stumble upon something worth mentioning on the Internet I just put it here.
Today the amount information that we get using various information streams is at massive overload. Thus one needs to focus only on what is important without the need to grep(1) the Internet everyday. Hence the idea of providing such information ‘bulk’ as I already do that grep(1).
The Usual Suspects section at the end is permanent and have links to other sites with interesting UNIX/BSD/Linux news.
Past releases are available at the dedicated NEWS page.
This year, I had the great privilege of receiving the FreeBSD Foundation travel grant to attend BSDCan.
The conference informally kicked off with the traditional gathering at the Father & Sons bar near the 90U residence on Tuesday. The first day of the FreeBSD developer summit opened with Nicholas Carlini’s talk about LLM-driven security analysis in the FreeBSD kernel, setting the tone for the remainder of the first devsummit day. Alpha-Omega’s Michael Winser continued this discussion from an open-source maintainer’s perspective, outlining strategies for dealing with the torrential influx of LLM-reported vulnerabilities. After a brief lunch break, the summit continued with Vince Milum’s presentation about building a Raspberry Pi-based GPS NTP server appliance using FreeBSD. The overview of his journey in applying FreeBSD to such an unorthodox use case was interesting and highlighted a few rough edges when using FreeBSD in embedded computing.
The summit continued with the Foundation’s yearly overview and an update from the srcmgr team, after which I spent some time catching up with a few colleagues in the hallways. The first day was capped off by a pizza dinner at the 90U lounge.
The second day of the devsummit began with an overview of the current state of the FreeBSD project’s infrastructure and the ongoing efforts to expand its use of cloud resources. After two “Have/Need/Want” planning sessions, I attended Olivier Certner’s talk about his ongoing work in the scheduler. The devsummit concluded with a round of shorter talks about planned work in the network stack, extended kernel errors, and virtual memory improvements from Netflix. The day concluded with a hacking session at the 90U lounge that lasted well into the night.
The first day of the conference began with Sean Howard’s talk about accessibility tooling that allowed them to use OpenBSD while recovering from eye surgery. Next up was Martin Vahlensieck’s talk about his new tool for creating temporary VMs on FreeBSD. After a short lunch break, I attended Henning Brauer’s talk about OpenNTPD and its now 20+ years of history. Following a short break in the quiet room, I attended Colin Percival’s talk about the turbulent FreeBSD 15.0 release process. The day once again concluded in the hacker lounge, where I also spent some time talking to Mark Johnston and John Baldwin about our ongoing srcmgr activities.
The final day of the conference began with Allan Jude’s talk about the recently introduced ZFS AnyRAID feature. Next up was Olivier Certner’s talk about the ongoing work to support hibernation on FreeBSD. The talk explored the implementation details in a lot of depth, and I was particularly astonished by the amount of groundwork needed to add proper hibernate support in the kernel. After lunch, I attended John Baldwin’s talk on thread-local storage. Another one of John’s fantastic ELF-related talks, it went into the gory details, behind TLS support in various parts of FreeBSD.
The penultimate talk of the day was another by Martin Vahlensieck, this time dealing with a deep dive into a seemingly trivial operation – writing to /dev/null. The talk was put together exceptionally well and did a great job of presenting complicated operating system concepts to a varied audience of users and developers. The last talk of the day was Jaeyoon Choi’s talk about adding Universal Flash Storage support to FreeBSD, after which we slowly started heading to the closing reception.
Attending this year’s BSDCan provided me with plenty of new project ideas for the near future and reinvigorated my drive to contribute to the project. Once again, thank you to the FreeBSD Foundation for sponsoring my attendance this year.
The ports repository has been frozen to revert a very large commit. There is no concern that the tree has been compromised. More information about the freeze can be found on the 2026 Ports Freeze page.
The home appliance giant LG Electronics USA said this week it plans to suspend any apps built for its smart TVs that turn one’s television into an always-on residential proxy node. The move comes less than a month after researchers found that more than 42 percent of games and other apps available for download on LG’s webOS store allow unknown third-parties to route their Internet traffic through a user’s TV.
Proxy SDK prevalence among smart TV apps for LG (webOS) and Samsung (Tizen OS) televisions. Image: Spur.us.
On July 2, we featured research by the security firm Spur that examined the prevalence of residential proxy software development kits (SDKs) in smart TV apps. Spur found more than 42 percent of apps available for download on LG smart TVs include SDKs that turn one’s television in a proxy node indefinitely, and that more than a quarter of the apps made for Samsung’s Tizen operating system had similar residential proxy components.
Responding to questions about Spur’s research, LG Senior Vice President John Taylor told KrebsOnSecurity the company was working with app developers to remove the residential proxy option from their apps on the webOS platform. Developers that fail to comply, he said, will find their apps suspended.
“A residential proxy network is not an intended use for LG smart TVs, and LG Electronics is working with developers to remove the residential proxy option from their apps on the webOS platform,” Taylor said. “If this option is not removed, these apps will be suspended.”
Taylor said LG is committed to keeping residential proxy networks out of its smart TV apps going forward, and that the company’s review of those apps is “well underway now.”
“As part of our ongoing efforts to enhance platform quality and the user experience, LG will continue to strengthen our evaluation process for developer-submitted apps, including those that incorporate residential proxy SDKs,” Taylor wrote in an emailed statement.
App makers looking for ways to monetize their creations can turn to residential proxy providers, which pay developers to include SDKs that turn the user’s device into a residential proxy node that is rented to paying customers. In the case of LG and Samsung smart TVs, Spur found residential proxy SDKs bundled with everything from simple games like Pac-Man to screensavers and file utilities.
A Pac-Man smart TV app from Bright Data offers users the choice between viewing ads in the game or agreeing to allow their TV to serve as a residential proxy node. Image: Spur.us.
Spur’s report found the residential proxy network Bright Data accounted for a majority of proxy SDKs across both Samsung and LG smart TVs. In a statement shared with KrebsOnSecurity, Bright Data said its network is built on consent and responsibility and operates by LG and Samsung terms.
“Every peer opts in through a dedicated screen and receives value in return; every customer is vetted, and our practices have now undergone a second independent audit by PwC,” the statement reads. “We remain committed to an open, transparent internet where legitimate businesses, researchers, and institutions can responsibly access data that lives in the public domain.”
Bright Data and other proxy providers named in Spur’s report all say they follow rigorous know-your-customer processes to validate legitimate uses of their services, which is often heavily tied to content-scraping activities by said customers. The proxy companies also say they incorporate technological countermeasures to prevent proxy service customers from being able to interact with and control other devices on the proxy user’s local network.
Spur argues the problem is not that residential proxy networks exist, but rather that they are being embedded at scale in devices that most consumers do not think of as computers and are not equipped to audit.
“A one-time consent prompt buried in a TV app is not a substitute for meaningful transparency, ongoing control, and platform oversight,” Spur’s Trevor Sutter wrote. “The risk is amplified when consent comes from individuals within the household who use the device but shouldn’t give consent, such as minors.”
LG’s announcement that it is culling residential proxy SDKs from its app store is welcome news, but the company recently came under fire for another questionable partnership: Pimping McAfee security products via software drivers included in its high-end LCD monitors.
Earlier this week, the Youtube channel Gamers Nexus showed that certain LG LCD monitors will automatically install an app that promotes paid McAfee antivirus subscriptions, and that the app arrives through Windows Update without an approval prompt.
Update, July 22, 1:06 p.m. ET: Added statement from Bright Data.
The June 2026 FreeBSD DevSummit & BSDCan was again successfully recorded and streamed through longtime streaming sponsor ScaleEngine. The requested DevSummit 2 question microphone system kept our running around to a minimum and fit the two rows of DMS1160. We got to see CheriBSD hardware again, in fact, Brooks Davis presented from a CheriBSD box. This year, the DevSummit focused more on AI integration than in previous years. Community member Warner Losh, in particular, gave an interesting talk about how he has used AI to help resolve an issue he was facing. I will refer you to the video posted to the FreeBSD YouTube channel for more details.
Community members Michael Williams and AV Lead Andrew Fengler lent us the mixing boards, which gave us the control we needed, so speakers, both low and enthusiastic, were heard clearly. This year’s hardware collection included community-donated hardware and personal hardware lent for the event. BSDCan fundraiser-in-chief Michael Dexter brought everything from home that the TSA would let him, and my bags were so full, I didn’t have room for my customary roll(s) of gaffer tape.
BSDCan has been successfully building attendee numbers year over year, with just shy of 170 for 2026. My fondest memory of the conference as part of the very hard working organization committee, was seeing Henning pull our shawarma vendor aside to deliver effusive praise for what many agreed was a fantastic lunch on Saturday.
Other highlights: – additional sleep support for the Framework laptop (Thank you, Devon!) – one of the smoothest AV team activations I have ever seen at a conference. – improved social media tie-in via both IRC and Discord (Many thanks to Charlie Li, Setesh, & and a team of Discord volunteers) – Nearly $2,000 raised for local charities.
Now, if you will excuse me, I have 4 days of videos to edit and post to the web. Be well, Patrick McEvoy bsdtv / bsdcan 2026 con chair
I’m really grateful to the FreeBSD Foundation for sponsoring my trip to BSDCan 2026 in Ottawa. The conference ran for four days — two days of DevSummit, then two days of the main conference, with many interesting talks throughout. For me, it’s mainly a chance to talk with developers I don’t otherwise get to reach in day-to-day work. This was my third time attending, and I was happy to be back again.
This year’s DevSummit felt a little different from previous years. A number of sessions touched on how AI is influencing project maintainability. Some of that influence is positive — vulnerability research came up as one example — but it’s also adding real burden on the reviewer side. Hearing different opinions from different people gave me a much broader view of the issue than I had going in.
This was also my first DevSummit as a src committer, so on day two, I got to take part in “Have Need Want” — the usual BSDCan session for this — and present my own work for review along with my plans for the next release. That covered updates to our USB stack, LLVM, CPU power throttling, and bhyve. I also got some feedback privately afterward, which drew a bit of welcome attention from other developers.
On the first day of the main conference, the talk I found most interesting was “Heterogeneous Scheduling on FreeBSD” by Minsoo Choo. It wasn’t really about the scheduler itself, but it got into something just as important: how heterogeneous core information should feed into the scheduler, and where and how that should happen. It reminded me that my CPU throttling work needs the same kind of information. Right now, the idea is to raise performance parameters as fast as possible under load, and back off while idle to save power. On a non-heterogeneous system, that only means tracking idle time. But on a heterogeneous system, cores differ in performance, which changes how we translate an abstract performance instruction into something a given core can act on — and that in turn affects how the cpufreq interface makes its decisions. I was glad to hear that there are already interfaces that provide heterogeneous-core hints for throttling, and I’m hoping to fold that into my future work.
On day two, I went to “Return of the Segment: Thread Local Storage” by jhb@. Since I also work on LLVM ELF internals, it was great to finally get a clear picture of how Thread Local Storage actually works under our libc++ ABI. jhb@ walked through it well — starting from thread-local errno and building up to a compiler-guided ELF TLS design. Afterward, we talked about whether we should move errno over to compiler-based TLS.
All in all, it was a great trip, with many good conversations with other developers. Thanks again to the Foundation for making it possible for me to be there.
1965 schrieb Gordon E. Moore den Artikel
“Cramming more components onto integrated circuits”
.
Darin beschreibt er die Beobachtung, die später, ungefähr ab 1975 durch Carver Mead,
als “Moore’s Law” bezeichnet wurde.
Moore’s Law sagt im Kern:
Alle x Monate verdoppelt sich die Anzahl der Komponenten in einem Prozessor, IC oder Chip,
den wir sinnvoll kostendeckend herstellen können.
Das genaue x ist für die Betrachtung gar nicht so wichtig.
Man findet 12, 18 oder 24 Monate als häufig zitierte Zahlen,
und Moore selbst hat über die Zeit unterschiedliche Basen verwendet.
Wichtig ist: Das war ein exponentielles Wachstum über Jahrzehnte.
Moore’s Beobachtung wurde in der Halbleiterindustrie erst zur Erwartung,
dann zur Selbstverpflichtung und schließlich zur Koordination der gesamten Supply Chain.
Seit 1992 veröffentlichte die US Semiconductor Industry Association die
National Technology Roadmap for Semiconductors.
Ab 1999 wurde daraus die ITRS, also eine globale Roadmap,
in der Chiphersteller, Zulieferer und Kunden gemeinsame Ziele für Density,
Power, Interconnects und Manufacturing Capabilities koordinierten.
Wie genau die Verdopplung erreicht wurde, hat sich mehrfach geändert.
Die Tatsache, dass sich pro sinnvoll herstellbarem Chip mehr Transistoren unterbringen ließen,
blieb lange erhalten.
Das erste harte Ende war Dennard Scaling
.
Vor ungefähr 2005 war es so:
Kleinere Transistoren brauchten weniger Spannung,
verbrauchten weniger Energie und erzeugten weniger Abwärme.
Man bekam also kleinere, schnellere und sparsamere Transistoren gleichzeitig.
Sehr bequem.
Um 2005 war das vorbei.
Die Taktfrequenzen stiegen nicht mehr sinnvoll weiter.
Stattdessen wechselte die Industrie von Single Core auf Multi Core.
Das war schmerzhaft.
Nahezu keine Software von 2005 konnte gut auf Multicore skalieren.
Es hat mehr als zehn Jahre gedauert,
bis breite Softwareentwicklung brauchbare Techniken hatte,
um den ganzen Bumms in einer CPU parallel, sinnvoll und halbwegs sicher zu verwenden.
Seitdem haben wir Performance per Watt als explizite Größe.
Vorher kam das quasi automatisch aus Dennard Scaling.
Seitdem haben wir auch Dark Silicon:
Teile eines Chips sind vorhanden,
können aber aus TDP-Gründen nicht gleichzeitig mit voller Leistung betrieben werden.
Man hat Transistoren, aber nicht genug thermisches Budget, um alle jederzeit zu benutzen.
Das zweite harte Ende kam um 2010.
Bis dahin wurden dichtere CPUs auch billiger pro Transistor.
Danach wurden die Herstellungsverfahren zwar weiter besser,
aber auch teurer.
Das führte zur Herstellerkonzentration.
Mit Intels Niedergang gibt es weltweit nur noch sehr wenige Firmen,
die Spitzenprozesse überhaupt herstellen können.
Im praktischen Sinne hängt sehr viel an TSMC.
TSMC wiederum existiert nicht als isolierte Zauberfabrik,
sondern als Knotenpunkt eines multinationalen Konsortiums aus Firmen,
Regierungen, Patenten, Maschinenbau und Supply Chain.
Seit 2015 ist der klassische ITRS-Roadmap-Prozess am Ende.
Traditionelles Moore’s Law ist damit ebenfalls am Ende.
Pro Sockel bekommen wir immer noch mehr.
Aber das ist inzwischen zu einem guten Teil Packaging:
mehrere Dies in einem Package,
Chiplets, gestapelte Speicher, Spezialbeschleuniger.
Das ist technisch beeindruckend.
Es ist aber nicht mehr dieselbe ökonomische Maschine wie früher.
Seit ungefähr 2010 bis 2015 ist der Compute-Bedarf im Haushalt ausentwickelt.
Selbst Videoschnitt als anspruchsvolle Haushaltsanwendung war auf einem Desktop möglich.
Mehr Compute war einem Heimanwender nicht mehr sinnvoll zu verkaufen.
Also hat man die Leistungsgewinne kleiner,
leiser und weniger leistungshungrig verpackt.
In 2026 kann man Videoschnitt auf einem Mobiltelefon machen,
mit einem Powerbudget im einstelligen Wattbereich.
E-Mail liest man nicht mehr an einem 150-Watt-Desktop mit Röhrenmonitor,
sondern auf einem Telefon, mit einem Verbrauch im Bereich von einigen hundert Milliwatt,
inklusive Netzwerk bis zum WLAN-AP oder Cell-Tower.
Der Heimmarkt ist saturiert.
Dasselbe gilt weitgehend für das Büro und große Teile der Enterprise-IT.
Nicht für HPC, Finite-Elemente-Analyse, Wettermodelle oder anderen Spezialkram.
Aber für sehr viel Large Scale Enterprise IT gilt:
2015 war das Angebot größer als der Bedarf.
Eine Analyse der Booking.com-Flottenworkload auf Instruction-Level zeigte 2018,
dass mehr als 80% des Computes Integer- oder String-Workloads waren.
“Lade Daten aus der Datenbank und setze sie in Templates ein” wird zu memcpy,
und memcpy wird zu REP MOVSB.
Booking war eine REP MOVSB-Maschine at scale.
Da war nahezu kein Bedarf an großen FPUs, SIMD-Instruktionen oder anderen Flächenfressern,
die auf höherwertigen Xeons viel Platz wegnehmen und viel Geld kosten.
Booking hätte von mehr Speicherbandbreite mehr profitiert als von noch tolleren CPUs.
Booking ist ein Webshop.
Bei einem sinnvoll konstruierten Webshop sieht das nicht grundsätzlich anders aus.
Ab 2015 ist auch viel Enterprise-IT im Compute-Bedarf ausentwickelt und abgedeckt.
Gleichzeitig wird der Druck auf Chiphersteller größer,
Anwendungen für all die Transistoren zu finden.
Die Fläche ist da.
Die Roadmap will weiter.
Also muss irgendetwas diese Transistoren fressen.
Wer am Ende der ITRS-Zeit in Roadmap-Meetings mit HPE, Dell und Intel saß,
kannte die Tonlage:
mehr FPU, AES- und RSA-Beschleuniger, FPGA-Accelerators,
Sonderfunktionen, Spezial-SKUs.
Kunde, sag uns bitte, wozu Du diese ganzen Dinger brauchen kannst.
Auf dem Heimanwendermarkt passiert dasselbe:
Desktop-CPUs mit 6, 12 oder 48 Cores,
3D V-Cache und anderem Zeug,
das außer Gamern und Spezialfällen kaum jemand braucht.
Irgendwie muss die Fläche voll werden.
Apple hat das Problem anders gelesen.
Man baut ein SoC und zieht alles auf den einen zentralen Die:
CPU, GPU, RAM-Anbindung, NVMe-Controller und möglichst viel sonstige Peripherie.
Neben der CPU sitzen nur noch wenige tief integrierte Bausteine.
Aktuelles iPhone. Nur der rot umrandete Bereich ist das Telefon, der Rest ist Batterie. Und im rot umrandeten Bereich sitzen im Grunde nur 2 Chips: Der SoC von Apple, ein A19 und ein SoC von Qualcomm für den ganzen Funk- und Analogmodem-Kram. Den will Apple gerne weg haben und durch was eigenes ersetzen, einmal weil sie Qualcomm nicht gerne Geld geben, und zum anderen weil sie den Kram nur dann mit dem A19 integrieren können.
Wenn ihr also glaubt,
dass ihr euren 2015er Laptop in 2026 noch benutzen könnt,
dann liegt das nicht daran, dass ihr besonders genügsam seid.
Es liegt daran, dass der Compute-Bedarf im Haushalt seit ungefähr 2015 saturiert ist.
Schlecht für eine Industrie,
die an dreijährige Replacement-Zyklen gewöhnt war.
Blockchain, Metaverse und AI kann man als Reihe erfundener Compute-Bedarfe lesen.
Das sind Wege,
mehr Nachfrage nach Compute zu synthetisieren,
um das Investorenmärchen von IT als ewiger Wachstumsbranche am Leben zu halten.
Nicht Mature Market, sondern Growth.
Nicht Dividende, sondern Aktienkursphantasie.
Nicht solide Firma, sondern Rakete.
Bei Blockchain und Metaverse sind die Blasen schnell geplatzt.
Das ist schlecht,
wenn man seine Silicon-Valley-Aktie gern als Wachstumsaktie halten möchte
und seine Entwickler-Divas mit Aktienpaketen bezahlen will.
Bei einem Mature Enterprise funktioniert das schlechter,
weil die Aktie nicht mehr automatisch explodiert.
Bei AI ist die Blase noch nicht geplatzt.
Aber die Financials darunter sind kaputt.
Da sind Ringfinanzierungen,
absurde Capex-Programme,
versprochene Effizienzgewinne,
die sich in dieser Größenordnung nicht realisieren lassen,
und ein Strom- und Hardwarebedarf,
der eher nach Schwerindustrie aussieht als nach Software-Marge.
Seit ungefähr 2015 hat die IT also eine Kapitalertragskrise.
Es gibt wortwörtlich Billionen an USD und EUR,
die Investitionsgelegenheiten brauchen,
damit sie weiter Kapitalertrag bringen.
Die Default-Antwort der letzten vierzig Jahre war “IT”.
Aber IT als breiter Markt ist saturiert.
Das ist die Verzweiflung,
die man riechen kann,
wenn man in diesem Markt gearbeitet hat.
Für Investoren ist AI ein maßgeschneidertes Versprechen.
Es parallelisiert sich hervorragend. Matrizenmultiplikation ist wie dafür gemacht.
Qualität wird mit größeren Modellen besser. Mehr ist mehr.
Riesenmodelle lassen sich zentral als AIaaS anbieten. Monatliche Mieterlöse, sehr schön.
Es gibt kein klar definiertes “fertig”.
Die Ersetzung des Menschen als Arbeitskraft klingt nach unendlichem Markt.
Endlich gibt es eine Anwendung für absurde Transistorbudgets.
Für viele Firmen ist AI zum letzten Investment geworden,
das sie je machen müssen.
Alle anderen Projekte werden minimiert,
eingestellt oder abgestoßen,
um mehr AI finanzieren zu können.
Oracle ist der deutlichste Fall:
Die Firma ist komplett von einem Erfolg der AI-Blase abhängig.
Wenn diese Blase platzt,
platzt Oracle mit.
Microsoft opfert sichtbar Teile des über Jahre konsolidierten Gaming-Business der AI.
Xbox, Game Pass und Studios werden sukzessive umgebaut,
abgewickelt oder ausgehöhlt.
Gaming wird sich davon nicht einfach erholen.
AAA-Gaming in der alten Form ist vorbei.
AI hat klaren Wert.
AI kann Effizienz steigern.
AI ist kein reiner Unsinn.
Aber AI kann diese absurden Investments nicht in dem Umfang zurückverdienen,
in dem sie gerade getätigt werden.
Das wird ein Blutbad.
Und es wird nicht auf IT-Werte beschränkt bleiben,
sondern auch Investmentfonds und Rentenfonds treffen.
Die Technik ist derzeit absurd ineffizient.
Wenn es gelingt,
sie um Faktor 100 effizienter zu machen,
dann ist das nur sieben Verdopplungen oder etwas mehr als drei Vervierfachungen.
Was heute auf einem 8x-Nvidia-Cluster läuft,
läuft dann auf einem großen Laptop.
Damit ist AIaaS als dauerhaftes Monopolmodell tot.
Es gibt auch kein US-Silicon-Valley-Monopol auf AI.
Chinesische Open-Weights-Modelle sind tödliche Raketen auf westliche Überinvestments.
Sie können die Blase platzen lassen,
weil sie genau den Burggraben zerstören,
den Investoren gerade kaufen zu glauben.
Gaming ist die gleiche Frage wie der Servermarkt,
nur marginal anders.
AAA-Gaming mit Windows-Kröte,
Nvidia-Grafikkarte und Spielen mit dreistelligem Millionenbudget ist eine Nische geworden.
Einigen wenigen PC-Master-Race-Ballermännern stehen Millionen Casual Gamer mit Mobiltelefonen gegenüber.
Der mobile Markt macht mehr und konstanteren Umsatz,
bei weniger Entwicklungsrisiko.
Unabhängig davon,
dass AI gerade Hardware auffrisst,
war PC-Gaming also schon angeschossen.
Corona hat kurz geholfen:
Mehr Spielstunden,
mehr Nachfrage,
mehr Hardwarekäufe.
Der Markt hat das als Strukturtrend gelesen und überinvestiert.
War aber ein Einmaleffekt.
Genau in die Korrektur kam dann der AI-Boom:
RAM wird teurer,
NVMe wird teurer,
GPUs werden für AI priorisiert,
und die Hersteller strangulieren den Enthusiast-PC-Markt,
weil AI-Chips höhere Margen versprechen.
Das zwingt den PC-Gaming-Markt zur Kontraktion.
Es wird Studios in die Pleite treiben.
Selbst wenn es jetzt sofort besser würde,
ist schon viel kaputt.
In fünf Jahren ist AAA/PC-Gaming in dieser Form vorbei.
Es kommt auch nicht einfach zurück.
2018 stellte Intel ungefähr zwei Millionen Xeon-Server-CPUs her.
AMD war zu diesem Zeitpunkt kaum noch auf dem Spielfeld.
Von diesen zwei Millionen gingen etwa 85% an zehn Firmen.
Mehr als 45% gingen an einen einzigen Kunden.
Die CPUs für diesen einen Kunden waren Spezial-SKUs mit Eigenschaften,
die normale Xeons zu diesem Zeitpunkt nicht hatten.
Einige davon fanden später mit Jahren Verzögerung ihren Weg in normale Produkte.
Eine Firma mit so einer Kundenstruktur ist nicht frei.
Sie bekommt Entwicklungsrichtung und Pricing von wenigen Großkunden diktiert.
Das ist im Kern krank.
Gleichzeitig ist Intel der letzte große CPU-Hersteller,1
der nicht TSMC ist.
Auch nicht gut.
Die ganze IT-Supply-Chain hängt an sehr wenigen Läden.
Das ist kein robuster Markt.
Das ist ein Klumpenrisiko mit PowerPoint.
Der IT-Markt,
mit dem viele von uns groß geworden sind,
ist seit ungefähr 2015 vorbei.
Was wir gerade beobachten,
ist eine Reihe von Blasen,
getrieben von Investorenverzweiflung.
Da ist sehr viel Kapital,
das nicht weiß wohin,
aber Erträge liefern muss.
Ein Teil gehört Einzelinvestoren.
Ein anderer Teil steckt in Fonds,
mit denen eine Generation Boomer ihren Ruhestand finanzieren will.
Genau in dem Moment geht der alte Motor aus.
Diese Krise ist technisch und finanziell sichtbar.
Alle gucken stur daran vorbei,
weil die naheliegenden Schlussfolgerungen politisch unangenehm sind.
Moore’s Law war nicht nur eine technische Beobachtung.
Es war vierzig Jahre lang eine industrielle Wachstumsmaschine.
Diese Maschine läuft nicht mehr wie früher.
Die AI-Blase ist der Versuch,
noch einmal einen Compute-Hunger zu erfinden,
der groß genug ist,
um die alte Wachstumsstory weiterzuerzählen.
Technisch gesehen gibt es noch Samsung, aber die machen keine Server- oder Desktop CPUs, sondern nur ARM für Mobilegeräte, und Speicher – aber das sind ganz andere Prozesse. ↩︎
[22:36 r730-03 dvl ~] % sudo pkg -j $MYJAIL upgrade -r FreeBSD-base
Updating FreeBSD-base repository catalogue...
FreeBSD-base repository is up to date.
FreeBSD-base is up to date.
Checking for upgrades (1 candidates): 100%
Processing candidates (1 candidates): 100%
Checking integrity... done (0 conflicting)
Your packages are up to date.
Upgrade the Base System
Don’t issue this command. See below.
[22:38 r730-03 dvl ~] % sudo pkg -j $MYJAIL -oABI=FreeBSD:15:$(uname -p) -oOSVERSION=1501000 upgrade -r FreeBSD-base
Updating FreeBSD-base repository catalogue...
pkg: Repository FreeBSD-base has a wrong packagesite, need to re-create database
[empty.int.unixathome.org] Fetching meta.conf: 100% 179 B 0.2 kB/s 00:01
[empty.int.unixathome.org] Fetching data: 100% 82 KiB 84.0 kB/s 00:01
Processing entries: 100%
FreeBSD-base repository update completed. 509 packages processed.
FreeBSD-base is up to date.
Checking for upgrades (312 candidates): 100%
Processing candidates (312 candidates): 100%
The following 321 package(s) will be affected (of 0 checked):
New packages to be INSTALLED:
FreeBSD-pam: 15.1 [FreeBSD-base]
FreeBSD-pam-dev: 15.1 [FreeBSD-base]
FreeBSD-pam-dev-lib32: 15.1 [FreeBSD-base]
...
FreeBSD-zoneinfo: 15.0p7 -> 15.1 [FreeBSD-base]
Installed packages to be REMOVED:
FreeBSD-lldb-dev: 15.0
Number of packages to be removed: 1
Number of packages to be installed: 10
Number of packages to be upgraded: 311
The process will require 2 MiB more space.
Proceed with this action? [y/N]: y
Checking integrity... done (0 conflicting)
pkg: Package FreeBSD-cron has files with flags that cannot be managed in this jail. Set allow.chflags in the jail configuration.
[22:41 r730-03 dvl ~] % sudo pkg -j $MYJAIL -oABI=FreeBSD:15:$(uname -p) -oOSVERSION=1501000 upgrade -r FreeBSD-base
Updating FreeBSD-base repository catalogue...
FreeBSD-base repository is up to date.
FreeBSD-base is up to date.
Checking for upgrades (312 candidates): 100%
Processing candidates (312 candidates): 100%
Checking integrity...
- FreeBSD-zstd-15.1 [FreeBSD-base] conflicts with FreeBSD-utilities-15.0p11 [installed] on /usr/bin/unzstd
- FreeBSD-clang-15.1p1 [FreeBSD-base] conflicts with FreeBSD-lldb-15.0p11 [installed] on /usr/lib/libprivatelldb.so.19
- FreeBSD-pam-lib-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-15.0p11 [installed] on /usr/lib/libpam.so.6
- FreeBSD-zstd-dev-lib32-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-dev-lib32-15.0p11 [installed] on /usr/lib32/libprivatezstd.a
- FreeBSD-pam-lib32-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-lib32-15.0p11 [installed] on /usr/lib32/libpam.so.6
- FreeBSD-pam-lib32-15.1 [FreeBSD-base] conflicts with FreeBSD-utilities-lib32-15.0p11 [installed] on /usr/lib32/pam_chroot.so
- FreeBSD-zstd-lib32-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-lib32-15.0p11 [installed] on /usr/lib32/libprivatezstd.so.5
- FreeBSD-zstd-lib-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-15.0p11 [installed] on /usr/lib/libprivatezstd.so.5
- FreeBSD-pam-dev-lib32-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-dev-lib32-15.0p11 [installed] on /usr/lib32/libpam.a
- FreeBSD-clang-dev-15.1p1 [FreeBSD-base] conflicts with FreeBSD-lldb-dev-15.0 [installed] on /usr/lib/libprivatelldb.so
- FreeBSD-zstd-dev-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-dev-15.0p11 [installed] on /usr/include/private/zstd/zstd.h
- FreeBSD-pam-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-15.0p11 [installed] on /etc/pam.d/README
- FreeBSD-pam-15.1 [FreeBSD-base] conflicts with FreeBSD-utilities-15.0p11 [installed] on /usr/lib/pam_chroot.so
- FreeBSD-pam-dev-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-dev-15.0p11 [installed] on /usr/include/security/openpam.h
Checking integrity... done (0 conflicting)
The following 322 package(s) will be affected (of 0 checked):
New packages to be INSTALLED:
FreeBSD-pam: 15.1 [FreeBSD-base]
FreeBSD-pam-dev: 15.1 [FreeBSD-base]
FreeBSD-pam-dev-lib32: 15.1 [FreeBSD-base]
FreeBSD-pam-lib: 15.1 [FreeBSD-base]
FreeBSD-pam-lib32: 15.1 [FreeBSD-base]
FreeBSD-zstd: 15.1 [FreeBSD-base]
FreeBSD-zstd-dev: 15.1 [FreeBSD-base]
FreeBSD-zstd-dev-lib32: 15.1 [FreeBSD-base]
FreeBSD-zstd-lib: 15.1 [FreeBSD-base]
FreeBSD-zstd-lib32: 15.1 [FreeBSD-base]
Installed packages to be UPGRADED:
FreeBSD-acct: 15.0 -> 15.1 [FreeBSD-base]
...
FreeBSD-zlib-lib32: 15.0 -> 15.1 [FreeBSD-base]
FreeBSD-zoneinfo: 15.0p7 -> 15.1 [FreeBSD-base]
Installed packages to be REMOVED:
FreeBSD-lldb-dev: 15.0
Number of packages to be removed: 1
Number of packages to be installed: 10
Number of packages to be upgraded: 311
The process will require 2 MiB more space.
Proceed with this action? [y/N]: y
[empty.int.unixathome.org] [ 1/327] Upgrading FreeBSD-bootloader from 15.0 to 15.1...
[empty.int.unixathome.org] [ 1/327] Extracting FreeBSD-bootloader-15.1: 100%
...
[empty.int.unixathome.org] [326/327] Extracting FreeBSD-tests-dbg-15.1p1: 100%
[empty.int.unixathome.org] [327/327] Installing FreeBSD-set-tests-15.1...
==> Running trigger: mandoc.ucl
Generating apropos(1) database for /usr/share/man...
Generating apropos(1) database for /usr/share/openssl/man...
=====
Message from FreeBSD-local-unbound-15.1:
--
After upgrading local-unbound, the configuration file should be regenerated
by running "service local_unbound setup" before restarting the service.
Upgrade Third-party Kernel Modules
This is a jail, no need to do this, but it does run.
[22:45 r730-03 dvl ~] % sudo pkg -j $MYJAIL upgrade -r FreeBSD-ports-kmods
Updating FreeBSD-ports-kmods repository catalogue...
[empty.int.unixathome.org] Fetching meta.conf: 100% 179 B 0.2 kB/s 00:01
[empty.int.unixathome.org] Fetching data: 100% 35 KiB 35.6 kB/s 00:01
Processing entries: 100%
FreeBSD-ports-kmods repository update completed. 239 packages processed.
FreeBSD-ports-kmods is up to date.
Updating database digests format: 100%
Checking for upgrades (0 candidates): 100%
Processing candidates (0 candidates): 100%
Checking integrity... done (0 conflicting)
Your packages are up to date.
[22:45 r730-03 dvl ~] %
NOTE: After running this from within the jail, I learned I should run it from the host and using the -j parameter. I’ll create a new blog post once I do another jail. PLEASE use thisupdated post instead.
[0:03 empty root ~] # ./pkgbasify.lua
...
Processing entries: 100%
FreeBSD-base repository update completed. 496 packages processed.
All repositories are up to date.
Overwrite //usr/local/etc/pkg/repos/FreeBSD-base.conf? (y/n) y
...
[empty.int.unixathome.org] [ 19/312] Extracting FreeBSD-bmake-15.0: 100%
[empty.int.unixathome.org] [ 20/312] Reinstalling FreeBSD-bootloader-15.0...
[empty.int.unixathome.org] [ 20/312] Extracting FreeBSD-bootloader-15.0: 9%
pkg: openat(boot/device.hints): No such file or directory
[empty.int.unixathome.org] [ 20/312] Extracting FreeBSD-bootloader-15.0: 100%
[empty.int.unixathome.org] [ 21/312] Reinstalling FreeBSD-bootloader-dev-15.0...
[empty.int.unixathome.org] [ 21/312] Extracting FreeBSD-bootloader-dev-15.0: 100%
...
[empty.int.unixathome.org] [ 32/312] Extracting FreeBSD-clibs-15.0p11: 100%
Cannot install /lib/libc.so.7, installed as /lib/libc.so.7.pkgnew
pkg: Failed to chflags /lib/libc.so.7:Operation not permitted
Error: exit
Restarting sshd
Performing sanity check on sshd configuration.
Stopping sshd.
Waiting for PIDS: 34877.
Performing sanity check on sshd configuration.
Starting sshd.
An error occurred during conversion leaving the system in a partially
converted state.
Please determine and resolve the root cause of the error.
When you believe the error will not happen again, run pkgbasify with
the --force argument to try and complete the conversion.
Well. OK then, let’s try:
[0:04 empty root ~] # ./pkgbasify.lua
Error: The system is already using pkgbase.
Pass --force to run pkgbasify anyway, for example to fix a partial conversion.
[0:06 empty root ~] # ./pkgbasify.lua --force
Running this tool will irreversibly modify your system to use pkgbase.
This tool and pkgbase are experimental and may result in a broken system.
It is highly recommended to backup your system before proceeding.
Do you accept this risk and wish to continue? (y/n) y
...
Processing entries: 100%
FreeBSD-base repository update completed. 496 packages processed.
All repositories are up to date.
Overwrite //usr/local/etc/pkg/repos/FreeBSD-base.conf? (y/n) y
...
An error occurred during conversion leaving the system in a partially
converted state.
Please determine and resolve the root cause of the error.
When you believe the error will not happen again, run pkgbasify with
the --force argument to try and complete the conversion.
[0:09 empty dvl ~] % sudo pkg upgrade
Updating FreeBSD-base repository catalogue...
FreeBSD-base repository is up to date.
Updating local repository catalogue...
local repository is up to date.
All repositories are up to date.
Checking for upgrades (13 candidates): 100%
Processing candidates (13 candidates): 100%
The following 12 package(s) will be affected (of 0 checked):
Installed packages to be UPGRADED:
bind-tools: 9.20.23 -> 9.20.24 [local]
curl: 8.20.0 -> 8.21.0 [local]
jq: 1.8.1 -> 1.8.2 [local]
libcbor: 0.13.0 -> 0.14.0 [local]
libcjson: 1.7.19 -> 1.7.19_1 [local]
libffi: 3.5.2 -> 3.6.0 [local]
libpsl: 0.21.5_2 -> 0.22.0 [local]
libssh2: 1.11.1,3 -> 1.11.1_1,3 [local]
mosquitto: 2.1.2_2 -> 2.1.2_3 [local]
p5-IO-Socket-SSL: 2.098 -> 2.099 [local]
rsync: 3.4.4 -> 3.4.4_1 [local]
zsh: 5.9_5 -> 5.9.1 [local]
Number of packages to be upgraded: 12
10 MiB to be downloaded.
Proceed with this action? [y/N]: y
[empty.int.unixathome.org] [ 1/12] Fetching mosquitto-2.1.2_3: 100% 476 KiB 487.7 kB/s 00:01
[empty.int.unixathome.org] [ 2/12] Fetching libcbor-0.14.0: 100% 83 KiB 85.4 kB/s 00:01
[empty.int.unixathome.org] [ 3/12] Fetching jq-1.8.2: 100% 340 KiB 348.5 kB/s 00:01
[empty.int.unixathome.org] [ 4/12] Fetching bind-tools-9.20.24: 100% 1579 KiB 1.6 MB/s 00:01
[empty.int.unixathome.org] [ 5/12] Fetching libpsl-0.22.0: 100% 66 KiB 68.1 kB/s 00:01
[empty.int.unixathome.org] [ 6/12] Fetching libcjson-1.7.19_1: 100% 39 KiB 39.5 kB/s 00:01
[empty.int.unixathome.org] [ 7/12] Fetching p5-IO-Socket-SSL-2.099: 100% 198 KiB 202.5 kB/s 00:01
[empty.int.unixathome.org] [ 8/12] Fetching rsync-3.4.4_1: 100% 401 KiB 410.3 kB/s 00:01
[empty.int.unixathome.org] [ 9/12] Fetching curl-8.21.0: 100% 1850 KiB 1.9 MB/s 00:01
[empty.int.unixathome.org] [10/12] Fetching zsh-5.9.1: 100% 5046 KiB 5.2 MB/s 00:01
[empty.int.unixathome.org] [11/12] Fetching libffi-3.6.0: 100% 50 KiB 51.0 kB/s 00:01
[empty.int.unixathome.org] [12/12] Fetching libssh2-1.11.1_1,3: 100% 244 KiB 249.6 kB/s 00:01
Checking integrity... done (0 conflicting)
[empty.int.unixathome.org] [ 1/12] Upgrading bind-tools from 9.20.23 to 9.20.24...
[empty.int.unixathome.org] [ 1/12] Extracting bind-tools-9.20.24: 100%
[empty.int.unixathome.org] [ 2/12] Upgrading jq from 1.8.1 to 1.8.2...
[empty.int.unixathome.org] [ 2/12] Extracting jq-1.8.2: 100%
[empty.int.unixathome.org] [ 3/12] Upgrading libcbor from 0.13.0 to 0.14.0...
[empty.int.unixathome.org] [ 3/12] Extracting libcbor-0.14.0: 100%
[empty.int.unixathome.org] [ 4/12] Upgrading libcjson from 1.7.19 to 1.7.19_1...
[empty.int.unixathome.org] [ 4/12] Extracting libcjson-1.7.19_1: 100%
[empty.int.unixathome.org] [ 5/12] Upgrading libffi from 3.5.2 to 3.6.0...
[empty.int.unixathome.org] [ 5/12] Extracting libffi-3.6.0: 100%
[empty.int.unixathome.org] [ 6/12] Upgrading libpsl from 0.21.5_2 to 0.22.0...
[empty.int.unixathome.org] [ 6/12] Extracting libpsl-0.22.0: 100%
[empty.int.unixathome.org] [ 7/12] Upgrading libssh2 from 1.11.1,3 to 1.11.1_1,3...
[empty.int.unixathome.org] [ 7/12] Extracting libssh2-1.11.1_1,3: 100%
[empty.int.unixathome.org] [ 8/12] Upgrading curl from 8.20.0 to 8.21.0...
[empty.int.unixathome.org] [ 8/12] Extracting curl-8.21.0: 100%
[empty.int.unixathome.org] [ 9/12] Upgrading mosquitto from 2.1.2_2 to 2.1.2_3...
===> Creating users
Using existing user 'nobody'
[empty.int.unixathome.org] [ 9/12] Extracting mosquitto-2.1.2_3: 100%
[empty.int.unixathome.org] [10/12] Upgrading p5-IO-Socket-SSL from 2.098 to 2.099...
[empty.int.unixathome.org] [10/12] Extracting p5-IO-Socket-SSL-2.099: 100%
[empty.int.unixathome.org] [11/12] Upgrading rsync from 3.4.4 to 3.4.4_1...
[empty.int.unixathome.org] [11/12] Extracting rsync-3.4.4_1: 100%
[empty.int.unixathome.org] [12/12] Upgrading zsh from 5.9_5 to 5.9.1...
[empty.int.unixathome.org] [12/12] Extracting zsh-5.9.1: 100%
You may need to manually remove /usr/local/etc/mosquitto/mosquitto.conf if it is no longer needed.
That seems good too.
So, what went wrong?
But wait, that error!
I just noticed this error, which appears in both of the last runs:
[empty.int.unixathome.org] [ 32/312] Extracting FreeBSD-clibs-15.0p11: 100%
Cannot install /lib/libc.so.7, installed as /lib/libc.so.7.pkgnew
pkg: Failed to chflags /lib/libc.so.7:Operation not permitted
Error: exit
Restarting sshd
I think chflags is still an issue.
Let’s try adding this to the jail configuration and restart it:
securelevel = -1;
This is the full run:
[0:29 empty root ~] # ./pkgbasify.lua --force
Running this tool will irreversibly modify your system to use pkgbase.
This tool and pkgbase are experimental and may result in a broken system.
It is highly recommended to backup your system before proceeding.
Do you accept this risk and wish to continue? (y/n) y
Updating FreeBSD-base repository catalogue...
FreeBSD-base repository is up to date.
Updating local repository catalogue...
local repository is up to date.
All repositories are up to date.
Checking integrity... done (0 conflicting)
Your packages are up to date.
Updating FreeBSD-ports repository catalogue...
[empty.int.unixathome.org] Fetching meta.conf: 100% 179 B 0.2 kB/s 00:01
[empty.int.unixathome.org] Fetching data: 100% 10 MiB 11.0 MB/s 00:01
Processing entries: 100%
FreeBSD-ports repository update completed. 37066 packages processed.
Updating FreeBSD-ports-kmods repository catalogue...
[empty.int.unixathome.org] Fetching meta.conf: 100% 179 B 0.2 kB/s 00:01
[empty.int.unixathome.org] Fetching data: 100% 35 KiB 35.9 kB/s 00:01
Processing entries: 100%
FreeBSD-ports-kmods repository update completed. 240 packages processed.
Updating FreeBSD-base repository catalogue...
[empty.int.unixathome.org] Fetching meta.conf: 100% 179 B 0.2 kB/s 00:01
[empty.int.unixathome.org] Fetching data: 100% 81 KiB 82.5 kB/s 00:01
Processing entries: 100%
FreeBSD-base repository update completed. 496 packages processed.
All repositories are up to date.
Overwrite //usr/local/etc/pkg/repos/FreeBSD-base.conf? (y/n) y
Overwriting //usr/local/etc/pkg/repos/FreeBSD-base.conf
Updating FreeBSD-base repository catalogue...
FreeBSD-base repository is up to date.
FreeBSD-base is up to date.
Checking integrity... done (0 conflicting)
The most recent versions of packages are already installed
Checking integrity... done (0 conflicting)
The most recent versions of packages are already installed
Checking integrity... done (0 conflicting)
The following 312 package(s) will be affected (of 0 checked):
Installed packages to be REINSTALLED:
FreeBSD-acct-15.0 [FreeBSD-base]
...
FreeBSD-zoneinfo-15.0p7 [FreeBSD-base]
Number of packages to be reinstalled: 312
[empty.int.unixathome.org] [ 1/312] Reinstalling FreeBSD-acct-15.0...
[empty.int.unixathome.org] [ 1/312] Extracting FreeBSD-acct-15.0: 100%
...
[empty.int.unixathome.org] [215/312] Reinstalling FreeBSD-caroot-15.0...
[empty.int.unixathome.org] [215/312] Extracting FreeBSD-caroot-15.0: 100%
certctl: legacy directory /etc/ssl/blacklisted can safely be deleted
[empty.int.unixathome.org] [216/312] Reinstalling FreeBSD-openssl-dev-15.0p10...
...
[empty.int.unixathome.org] [311/312] Extracting FreeBSD-tests-dbg-15.0p11: 100%
[empty.int.unixathome.org] [312/312] Reinstalling FreeBSD-set-tests-15.0...
==> Running trigger: mandoc.ucl
=====
Message from FreeBSD-local-unbound-15.0p10:
--
After upgrading local-unbound, the configuration file should be regenerated
by running "service local_unbound setup" before restarting the service.
Restarting sshd
Performing sanity check on sshd configuration.
Stopping sshd.
Waiting for PIDS: 50722.
Performing sanity check on sshd configuration.
Starting sshd.
Conversion finished.
Please verify that the contents of the following critical files are as expected:
/etc/master.passwd
/etc/group
/etc/ssh/sshd_config
After verifying those files, restart the system.
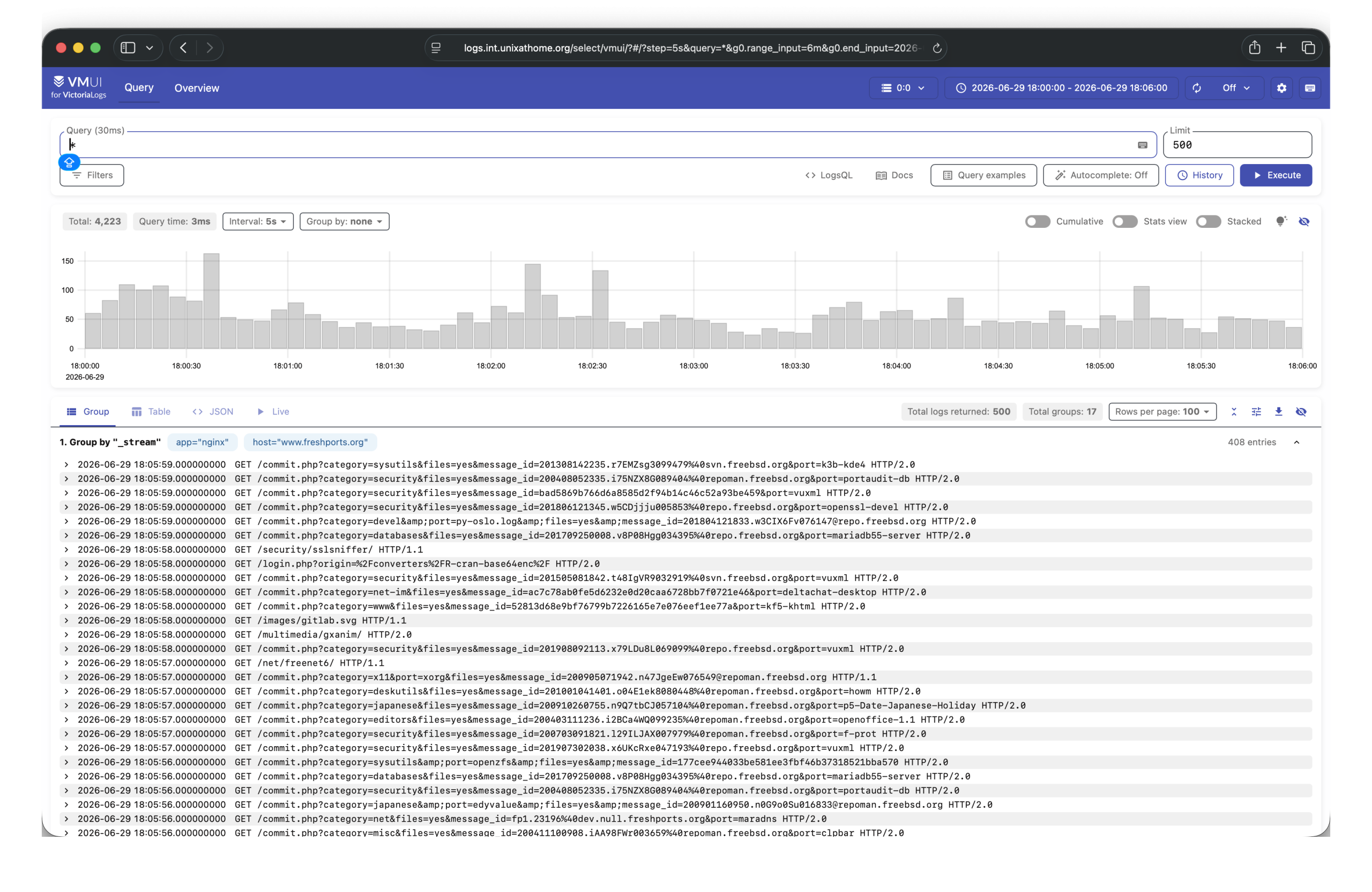
The Valuable News weekly series is dedicated to provide summary about news, articles and other interesting stuff mostly but not always related to the UNIX/BSD/Linux systems. Whenever I stumble upon something worth mentioning on the Internet I just put it here.
Today the amount information that we get using various information streams is at massive overload. Thus one needs to focus only on what is important without the need to grep(1) the Internet everyday. Hence the idea of providing such information ‘bulk’ as I already do that grep(1).
The Usual Suspects section at the end is permanent and have links to other sites with interesting UNIX/BSD/Linux news.
Past releases are available at the dedicated NEWS page.
This post is an excerpt from the formally non-public part of myDFG Heisenberg
grant final report (about half of the actually interesting part). I
hope it will help people do better. Some personal information has been
redacted.
The backstory
In 2018, when I first submitted a Heisenberg program proposal,
funding was declined. One referee report was full of misinformation and
misinterpretations, the other criticized the methods in one of the
suggested research subtopics. Overall this sufficiently lowered the
ranking of the entire submission. Anyway, as the saying goes, stand up
again, brush down coat, re-adjust crown, keep going. The proposal was
updated, the doubtful part replaced, a response to the misinformation
added, and of course also some more exciting research ideas included.
At that point I decided to go for full risk. While the DFG Emmy
Noether program deliberately funds a junior research group consisting of
a PI and PhD students or a post-doc, the DFG Heisenberg program is more
adjusted along the customs of humanities and funds the PI alone. It is
still supposed to provide a base for independent research at the level
of associate professor though, which is why one can concurrently submit a
supporting research grant proposal for equipment and personnel. The
advantage of doing so is that this can form a coherent overall funding
package, the disadvantage is that a negative review of any part of the
package will drag it down in its entirety, see above.
Complementing the overarching Heisenberg proposal for my own
position and its research, I submitted in 2019 two additional research
proposals ("Einzelanträge"). One focused on the continuation of the Emmy
Noether project, tuning optomechanics of single-wall carbon nanotubes
towards strong coupling and coherent control, and including such nice
ideas as, e.g., coupling mechanics with coherent states in double
quantum dots. This was a highly complex project, intended for two PhD
students (and the two students were really required because of the
combination of multi-step fabrication and complicated experiment). In
addition, it was adjusted to fit to the topic of a Graduate Research
School (GRK) proposal under preparation back then in Regensburg. The
idea of the second grant was to try out something new, and establish
quantum transport measurements on MoS2 nanotubes – a material where
already a lot of optical measurements existed but the transport physics
of quantum dots was so far completely unexplored. Here, one PhD student
was requested; furthermore the topic was deliberately chosen to be in
the area of interest of a new Regensburg Collaborative Research Centre
(SFB), SFB 1277, in the hope of further financial support options.
Because of the significant amount of university-bound equipment
acquired from SFB funds, and the potential difficulties of moving “my”
large dilution refrigerator, I chose again Universität Regensburg as
host institution.
In the meantime, my employment contract in Regensburg ran out
(thanks Wissenschaftszeitvertragsgesetz), so I went to the Low
Temperature Laboratory, Department of Applied Physics, Aalto University,
Finland for one year as full-time employed visiting professor; my
thanks go to Prof. Pertti Hakonen for making this possible. Two weeks
later COVID broke out, but Aalto was a great place to be both
scientifically and to sit out the pandemic. And in autumn a sequence of
excellent news followed; the Heisenberg grant was approved, and in
addition the Emmy Noether work on microwave optomechanics was awarded
the Walter Schottky Prize 2021 of the German Physical Society. So, things were clearly brightening up, or so I thought.
A more detailed inspection of the grant approval letter provided a
somewhat more mixed image. One referee explicitly and clearly supported
the request for two PhD students in the optomechanics project, the
other also explicitly lauded all details, including the excellent
funding plan, of the optomechanics project, but additionally stated that
the impact of the MoS2 nanotube project would be larger (this was
likely written before the announcement of the Walter Schottky Prize). As
result, only one PhD position for optomechanics was granted by the
funding committee. Hope always dies last, but in retrospect I can now
confirm my immediate suspicion that this reduction of funding killed the
optomechanics project from the start. My initial “plan B” for
additional optomechanics funds was not available anymore, since the
Regensburg Graduate Research School had in the meantime made an
ultrafast turn towards other research topics. Further, even though this
project was the direct continuation of the Walter Schottky Prize work,
it turned out to be extremely difficult to find and hire a PhD student
for it. The project started on 16 March 2021, and only on 1 August 2022 a
PhD student arrived.
In comparison, the MoS2 nanotube project start-up went much more
smooth, and [...] started work on his PhD straight on the 16 March 2021.
All hope of a financially significant participation in the Regensburg
SFB 1277 was however shattered already by a brief conversation with the
back then SFB speaker, who made clear that nothing beyond appointing me
“associated member” would even be considered. Well, you can't allow
“junior scientists” to become too successful…
Scientific progress
I had attempted to keep the optomechanics project going in
Regensburg during my time in Finland via a remotely-supervised MSc
student, who successfully optimized coplanar waveguide resonator
geometries and produced and tested the corresponding devices. When I
came back, I quickly found another MSc student who was very enthusiastic
to start with optomechanics experiments. However, we also quickly found
out that the nanotube growth oven had broken in the meantime, requiring
the whole process to be optimized from the start, and the MSc project
literally became a year of getting carbon nanotube growth going again
from zero. Now in 2026 (!) the quality of nanotubes transferred into a
circuit is finally showing excellent results again. That said, the
nanotube optomechanics project had many delicate parts, from nanotube
growth and transfer to coplanar resonator chip design and fabrication,
and no number of MSc students recruited into my group could really
replace the missing second PhD student.
[...] On the MoS2 nanotube side, progress was slow but steady,
and the PhD student did excellent work. Making contacts to MoS2
nanotubes turned out to be even more complex than contacts to carbon
nanotubes or a 2D MoS2 monolayer. A technical breakthrough in the latter
system by researchers from MIT and TSMC, among others, provided a path
forward, and indeed their approach also led to occasional good results
with the MoS2 nanotubes. Obtaining these good results reproducibly,
however, was again another complex optimization step; we solved that in
2025 and subsequently managed first physically interesting
low-temperature measurements.
In general, across both subprojects, work was slowed down very
much by continuous equipment break-downs and oddities in the Regensburg
cleanroom. "The SEM for e-beam writing is down" turned out to be one
highly regular e-mail subject (for any possible value of "the SEM").
Mystery changes in resist properties, micrometer-scale shifts in the
written structures, interruptions in the air conditioning that led to
water condensation in the whole cleanroom, ... The department bought a
Heidelberg Instruments mask-less aligner (a laser writer for
lithography), which was nice but of limited usefulness – since for
nanophysics you actually need nano-resolution! Plus there were some
other annoying events; e.g., during the installation of a new dilution
refrigerator next door someone opened up our (then evacuated) 3He/4He
circuit in the pump room to air, which we only noticed when we tried to
cool down and suddenly were pumping air into the cold dilution
refrigerator insert. Luckily, nearly no isotope mixture was lost.
Experimental work took significantly longer than expected, but
eventually did yield interesting results right at the end. As stated
above, for the research details of the two subprojects, I refer to the
final reports of the research grants [...] and [...].
[...]
Early career stage researchers
I am proud to be able to say that during my ~16 years in
Regensburg I have supervised 7 PhD students and 27 MSc or Diplom
students. During the Heisenberg period specifically, two PhD students
should be named, [...] and [...]. [...] is currently helping a new
professor in Regensburg build up his lab on a post-doc position and
considering remaining in academia (which he would definitely be suited
for). [...] is still busy measuring beautiful data and writing up his
dissertation, while being paid by SFB1277.
At the end of the official project runtime (and my employment) in
March three MSc students were still active; two have graduated by now,
the third one recently handed in his thesis.
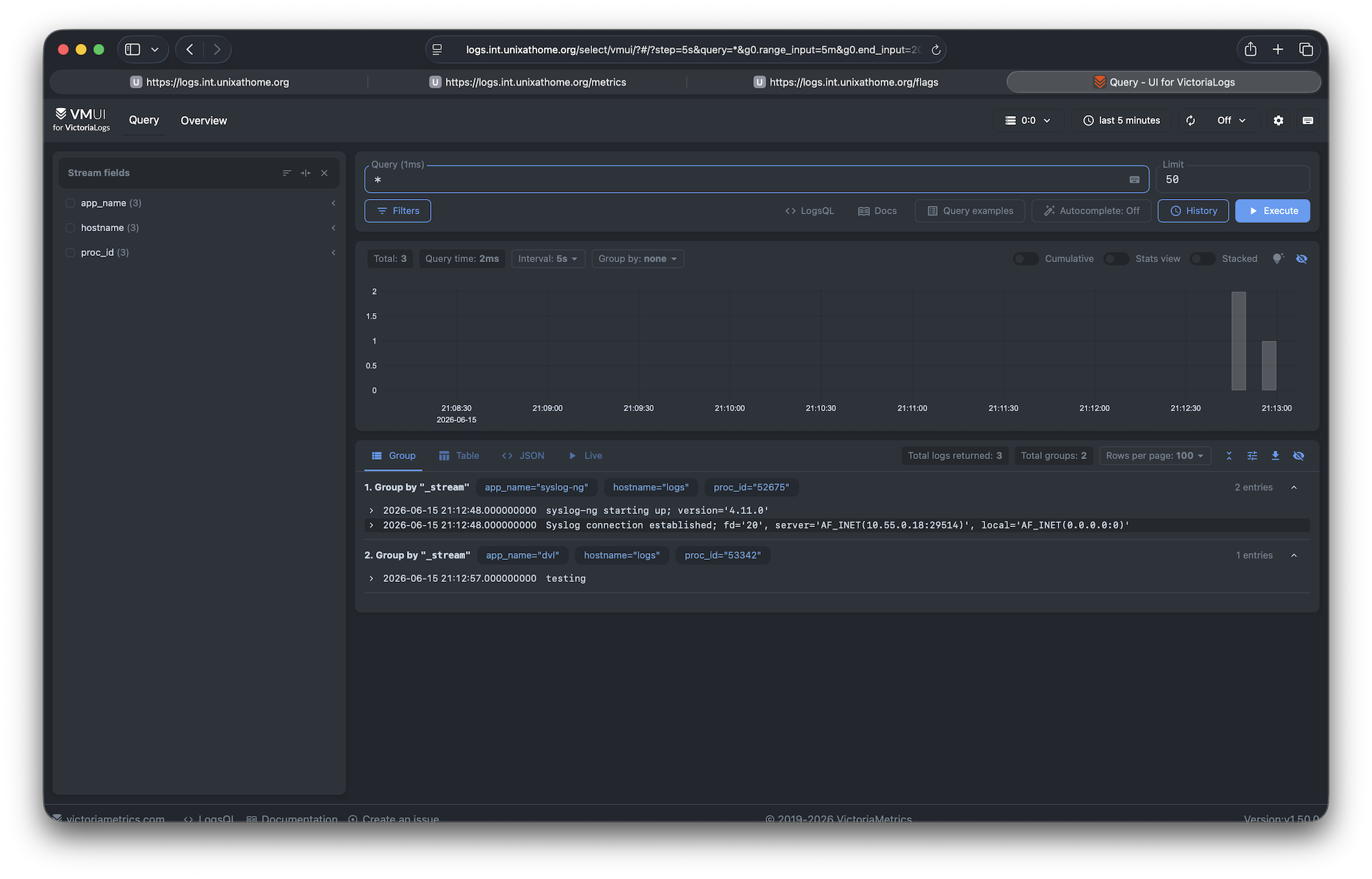
While doing some performance tracing of an application with the FreeBSD hwpmc subsystem as a normal user in a jail, I tripped over a kernel crash (this only happens if INVARIANTS is compiled into the kernel, so not with a RELEASE kernel).
I reported that about a week ago on the FreeBSD-current mailing list. I got feedback with a suspicion, but nothing specific.
Last night the same system crashed again, this time in nullfs (and again, this only happens if INVARIANTS is compiled into the kernel, so not with a RELEASE kernel).
As I was playing around with Claude Code (this performance tracing), and already had a nice setup (one week of teaching Claude “my way” of using WSL, compilers, some developer tools, a development and testing methodology, connect to particular FreeBSD jails and the tools to use there, create unit tests, spin-up test VMs, build harnesses, test harnesses, and so on), I thought I should give Claude (Fable) temporary read access to the git tree of the crashed kernel, the coredump and the debug symbols. Here is what it did:
Stage
Duration
Notes
Analysis & root-cause (both panics)
~27 min
Implement + verify-build + stage 2 patches
~5 min
builds were 31 s + 11 s of it
Hardening (reviewer/width research, ATF test, reproducers, review by user)
incl. finalizing the other two patches; build 30 s
Rig validation of 3rd patch (build + deploy + test)
~10 min
Totals
~2 h 14 min
wall clock ~4 h 42 min (usage limit exceeded)
This included some back-and-forth with me, some questions from and to me, and some decisionsby me (I have some guidelines for Claude to discuss some stuff with me instead of blindly going forward, and I reviewed the output and sometimes intervene directly when I don’t like something).
The results were opened for review, and some moments ago (less than 12h since I noticed it this morning) I committed the fix for the nullfs issue (no unit test, as this was a race issue and may run for a long time before triggering). The other two hwpmc issues are under review (including unit-tests).
About 2h to fix three kernel crashes, including reproducer/unit-tests (we will see if the reviewers are OK with the fix or not, but at least it does not panic my system anymore).
I have to say I’m impressed. I didn’t expect much, I told Claude to have a go at it, went to take a shower, and came back to see Claude had validated the reproducer for the nullfs+inotify issue, and a unit-test for the first issue (which then crashed into the 3rd issue).
This was the fastest turnaround for a fix of one of the crashes I was able to trigger on my systems. Well… three fixes for three crashes.
I decided that Thursday morning at 8:27 AM was the right time to start my first update from FreeBSD 15.0 to 15.1 – all my hosts are now on pkgbase. I used the pgkbasify script. Now it’s time to update again.
[12:33 nagios04 root ~] # pkg upgrade -r FreeBSD-base
Updating FreeBSD-base repository catalogue...
FreeBSD-base repository is up to date.
FreeBSD-base is up to date.
Checking for upgrades (1 candidates): 100%
Processing candidates (1 candidates): 100%
Checking integrity... done (0 conflicting)
Your packages are up to date.
Upgrade the Base System
The main thing to take note of in the paste below, this removal. Everything else seems OK. Turns out, it was of no consequence
Installed packages to be REMOVED:
FreeBSD-lldb-dev: 15.0
[12:34 nagios04 root ~] # pkg -oABI=FreeBSD:15:$(uname -p) -oOSVERSION=1501000 upgrade -r FreeBSD-base
Updating FreeBSD-base repository catalogue...
pkg: Repository FreeBSD-base has a wrong packagesite, need to re-create database
Fetching meta.conf: 100% 179 B 0.2 kB/s 00:01
Fetching data: 100% 82 KiB 84.0 kB/s 00:01
Processing entries: 100%
FreeBSD-base repository update completed. 509 packages processed.
FreeBSD-base is up to date.
Checking for upgrades (486 candidates): 100%
Processing candidates (486 candidates): 100%
The following 499 package(s) will be affected (of 0 checked):
New packages to be INSTALLED:
FreeBSD-pam: 15.1 [FreeBSD-base]
FreeBSD-pam-dbg: 15.1 [FreeBSD-base]
FreeBSD-pam-dbg-lib32: 15.1 [FreeBSD-base]
FreeBSD-pam-dev: 15.1 [FreeBSD-base]
FreeBSD-pam-dev-lib32: 15.1 [FreeBSD-base]
FreeBSD-pam-lib: 15.1 [FreeBSD-base]
FreeBSD-pam-lib32: 15.1 [FreeBSD-base]
FreeBSD-zstd: 15.1 [FreeBSD-base]
FreeBSD-zstd-dbg: 15.1 [FreeBSD-base]
FreeBSD-zstd-dbg-lib32: 15.1 [FreeBSD-base]
FreeBSD-zstd-dev: 15.1 [FreeBSD-base]
FreeBSD-zstd-dev-lib32: 15.1 [FreeBSD-base]
FreeBSD-zstd-lib: 15.1 [FreeBSD-base]
FreeBSD-zstd-lib32: 15.1 [FreeBSD-base]
Installed packages to be UPGRADED:
FreeBSD-acct: 15.0 -> 15.1 [FreeBSD-base]
FreeBSD-acct-dbg: 15.0 -> 15.1 [FreeBSD-base]
FreeBSD-acpi: 15.0 -> 15.1 [FreeBSD-base]
...
FreeBSD-zlib-lib32: 15.0 -> 15.1 [FreeBSD-base]
FreeBSD-zoneinfo: 15.0p7 -> 15.1 [FreeBSD-base]
Number of packages to be installed: 14
Number of packages to be upgraded: 485
The process will require 12 MiB more space.
672 MiB to be downloaded.
Proceed with this action? [y/N]: y
[ 1/499] Fetching FreeBSD-libmilter-dev-15.1: 100% 86 KiB 87.8 kB/s 00:01
...
[499/499] Fetching FreeBSD-ctf-dev-15.1: 100% 138 KiB 141.1 kB/s 00:01
Checking integrity... done (24 conflicting)
- FreeBSD-sound-15.1 [FreeBSD-base] conflicts with FreeBSD-rc-15.0 [installed] on /etc/rc.d/mixer
- FreeBSD-atf-15.1 [FreeBSD-base] conflicts with FreeBSD-tests-15.0p11 [installed] on /usr/share/atf/libatf-sh.subr
- FreeBSD-pam-dbg-lib32-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-dbg-lib32-15.0p11 [installed] on /usr/lib/debug/usr/lib32/libpam.so.6.debug
- FreeBSD-pam-dbg-lib32-15.1 [FreeBSD-base] conflicts with FreeBSD-utilities-dbg-lib32-15.0p11 [installed] on /usr/lib/debug/usr/lib32/pam_chroot.so.6.debug
- FreeBSD-zstd-15.1 [FreeBSD-base] conflicts with FreeBSD-utilities-15.0p11 [installed] on /usr/bin/unzstd
- FreeBSD-pam-dbg-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-dbg-15.0p11 [installed] on /usr/lib/debug/usr/lib/libpam.so.6.debug
- FreeBSD-pam-dbg-15.1 [FreeBSD-base] conflicts with FreeBSD-utilities-dbg-15.0p11 [installed] on /usr/lib/debug/usr/lib/pam_chroot.so.6.debug
- FreeBSD-clang-15.1p1 [FreeBSD-base] conflicts with FreeBSD-lldb-15.0p11 [installed] on /usr/lib/libprivatelldb.so.19
- FreeBSD-pam-lib-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-15.0p11 [installed] on /usr/lib/libpam.so.6
- FreeBSD-zstd-dev-lib32-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-dev-lib32-15.0p11 [installed] on /usr/lib32/libprivatezstd.a
- FreeBSD-pam-lib32-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-lib32-15.0p11 [installed] on /usr/lib32/libpam.so.6
- FreeBSD-pam-lib32-15.1 [FreeBSD-base] conflicts with FreeBSD-utilities-lib32-15.0p11 [installed] on /usr/lib32/pam_chroot.so
- FreeBSD-zstd-lib32-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-lib32-15.0p11 [installed] on /usr/lib32/libprivatezstd.so.5
- FreeBSD-zstd-lib-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-15.0p11 [installed] on /usr/lib/libprivatezstd.so.5
- FreeBSD-pam-dev-lib32-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-dev-lib32-15.0p11 [installed] on /usr/lib32/libpam.a
- FreeBSD-zstd-dbg-lib32-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-dbg-lib32-15.0p11 [installed] on /usr/lib/debug/usr/lib32/libprivatezstd.so.5.debug
- FreeBSD-clang-dbg-15.1p1 [FreeBSD-base] conflicts with FreeBSD-lldb-dbg-15.0p11 [installed] on /usr/lib/debug/usr/lib/libprivatelldb.so.19.debug
- FreeBSD-clang-dev-15.1p1 [FreeBSD-base] conflicts with FreeBSD-lldb-dev-15.0 [installed] on /usr/lib/libprivatelldb.so
- FreeBSD-zstd-dev-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-dev-15.0p11 [installed] on /usr/include/private/zstd/zstd.h
- FreeBSD-pam-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-15.0p11 [installed] on /etc/pam.d/README
- FreeBSD-pam-15.1 [FreeBSD-base] conflicts with FreeBSD-utilities-15.0p11 [installed] on /usr/lib/pam_chroot.so
- FreeBSD-zstd-dbg-15.1 [FreeBSD-base] conflicts with FreeBSD-utilities-dbg-15.0p11 [installed] on /usr/lib/debug/usr/bin/zstd.debug
- FreeBSD-zstd-dbg-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-dbg-15.0p11 [installed] on /usr/lib/debug/usr/lib/libprivatezstd.so.5.debug
- FreeBSD-pam-dev-15.1 [FreeBSD-base] conflicts with FreeBSD-runtime-dev-15.0p11 [installed] on /usr/include/security/openpam.h
Checking integrity... done (0 conflicting)
Conflicts with the existing packages have been found.
One more solver iteration is needed to resolve them.
The following 500 package(s) will be affected (of 0 checked):
New packages to be INSTALLED:
FreeBSD-pam: 15.1 [FreeBSD-base]
FreeBSD-pam-dbg: 15.1 [FreeBSD-base]
FreeBSD-pam-dbg-lib32: 15.1 [FreeBSD-base]
FreeBSD-pam-dev: 15.1 [FreeBSD-base]
FreeBSD-pam-dev-lib32: 15.1 [FreeBSD-base]
FreeBSD-pam-lib: 15.1 [FreeBSD-base]
FreeBSD-pam-lib32: 15.1 [FreeBSD-base]
FreeBSD-zstd: 15.1 [FreeBSD-base]
FreeBSD-zstd-dbg: 15.1 [FreeBSD-base]
FreeBSD-zstd-dbg-lib32: 15.1 [FreeBSD-base]
FreeBSD-zstd-dev: 15.1 [FreeBSD-base]
FreeBSD-zstd-dev-lib32: 15.1 [FreeBSD-base]
FreeBSD-zstd-lib: 15.1 [FreeBSD-base]
FreeBSD-zstd-lib32: 15.1 [FreeBSD-base]
Installed packages to be UPGRADED:
FreeBSD-acct: 15.0 -> 15.1 [FreeBSD-base]
...
FreeBSD-zoneinfo: 15.0p7 -> 15.1 [FreeBSD-base]
Installed packages to be REMOVED:
FreeBSD-lldb-dev: 15.0
Number of packages to be removed: 1
Number of packages to be installed: 14
Number of packages to be upgraded: 485
The process will require 12 MiB more space.
Proceed with this action? [y/N]: y
Checking integrity... done (0 conflicting)
[ 1/507] Upgrading FreeBSD-bootloader from 15.0 to 15.1...
[ 1/507] Extracting FreeBSD-bootloader-15.1: 100%
...
[506/507] Installing FreeBSD-set-optional-dbg-15.1...
[507/507] Installing FreeBSD-set-base-dbg-15.1...
==> Running trigger: mandoc.ucl
Generating apropos(1) database for /usr/share/man...
Generating apropos(1) database for /usr/share/openssl/man...
=====
Message from FreeBSD-local-unbound-15.1:
--
After upgrading local-unbound, the configuration file should be regenerated
by running "service local_unbound setup" before restarting the service.
Upgrade Third-party Kernel Modules
[12:43 nagios04 root ~] # pkg upgrade -r FreeBSD-ports-kmods
Updating FreeBSD-ports-kmods repository catalogue...
pkg: Repository FreeBSD-ports-kmods has a wrong packagesite, need to re-create database
Fetching meta.conf: 100% 179 B 0.2 kB/s 00:01
Fetching data: 100% 35 KiB 35.6 kB/s 00:01
Processing entries: 100%
FreeBSD-ports-kmods repository update completed. 239 packages processed.
FreeBSD-ports-kmods is up to date.
Checking for upgrades (0 candidates): 100%
Processing candidates (0 candidates): 100%
Checking integrity... done (0 conflicting)
Your packages are up to date.
[12:44 nagios04 root ~] #
[16:13 nagios04 root ~] # mount | grep /boot/efi
/dev/gpt/efiboot0 on /boot/efi (msdosfs, local)
Finish
Before you reboot, I didn’t do the following on this host, but I did on the next host. I set the BE to boot one time (-t). In case there was a problem, the next boot would be back on FreeBSD 15.0. This is how I did that:
[16:42 r730-03 root ~] # bectl list
BE Active Mountpoint Space Created
15.0-RELEASE-p9_2026-06-10_111727 - - 468M 2026-06-10 11:17
default NR / 15.1G 2023-08-10 21:51
pre-15.1 - - 948K 2026-07-17 16:37
pre-pkgbasify_2026-06-30_152431 - - 397M 2026-06-30 15:24
[16:42 r730-03 root ~] # bectl activate pre-15.1
Successfully activated boot environment pre-15.1
[16:42 r730-03 root ~] # bectl activate -t default
Successfully activated boot environment default for next boot
[16:42 r730-03 root ~] # sudo shutdown -r now
Shutdown NOW!
shutdown: [pid 37935]
....
[12:46 pro05 dvl ~] % r730-03
Last login: Fri Jul 17 16:37:25 2026 from pro05.startpoint.vpn.unixathome.org
[16:46 r730-03 dvl ~] % uptime
4:46PM up 42 secs, 1 user, load averages: 0.35, 0.09, 0.03
[16:46 r730-03 dvl ~] % freebsd-version -ukr
15.1-RELEASE-p1
15.1-RELEASE-p1
15.1-RELEASE-p1
[16:46 r730-03 dvl ~] % uname -a
FreeBSD r730-03.int.unixathome.org 15.1-RELEASE-p1 FreeBSD 15.1-RELEASE-p1 releng/15.1-n283582-0f691888dc56 GENERIC amd64
[16:46 r730-03 dvl ~] % bectl list
BE Active Mountpoint Space Created
15.0-RELEASE-p9_2026-06-10_111727 - - 468M 2026-06-10 11:17
default N / 1.49G 2023-08-10 21:51
pre-15.1 R - 13.6G 2026-07-17 16:37
pre-pkgbasify_2026-06-30_152431 - - 397M 2026-06-30 15:24
[16:46 r730-03 dvl ~] % sudo bectl activate default
Successfully activated boot environment default
[16:47 r730-03 dvl ~] % bectl list
BE Active Mountpoint Space Created
15.0-RELEASE-p9_2026-06-10_111727 - - 468M 2026-06-10 11:17
default NR / 15.1G 2023-08-10 21:51
pre-15.1 - - 952K 2026-07-17 16:37
pre-pkgbasify_2026-06-30_152431 - - 397M 2026-06-30 15:24
[16:47 r730-03 dvl ~] %
I’m happy with the boot, so I made default the next boot for the BE.
This is what I did with this host:
[16:14 nagios04 root ~] # shutdown -r now
Shutdown NOW!
shutdown: [pid 7690]
[16:14 nagios04 root ~] #
*** FINAL System shutdown message from dvl@nagios04.unixathome.org ***
System going down IMMEDIATELY
*** FINAL System shutdown message from dvl@nagios04.unixathome.org ***
System going down IMMEDIATELY
System shutdown time has arrived
Connection to nagios04.unixathome.org closed by remote host.
Connection to nagios04.unixathome.org closed.
[12:15 pro05 dvl ~] %
During BSDCan, the FreeBSD Foundation holds its annual meeting and Board elections. Following this year’s meeting, we are pleased to welcome Dave Cottlehuber to the FreeBSD Foundation Board of Directors. Take a minute to read this interview with Dave to learn more about his involvement with FreeBSD and why he joined the Foundation Board of Directors.
This transition also provides an opportunity to explain how the Foundation Board operates, how board members are elected, and how the Board’s role differs from Foundation staff and FreeBSD Project leadership. These distinctions are not always obvious from the outside, and we want to provide a clearer explanation of how the Foundation is governed.
The Foundation Board exists to help the organization make thoughtful, responsible decisions for the long term. It brings together people with different experiences and perspectives to help the Foundation stay focused, accountable, and connected to the broader FreeBSD ecosystem.
Project Leadership, Foundation Staff, and the Foundation Board
The FreeBSD Foundation is part of the broader FreeBSD ecosystem, working alongside the FreeBSD Project, contributors, users, companies, and community members to help FreeBSD thrive.
The FreeBSD Project leads the operating system’s technical direction, including the source tree, releases, technical priorities, and Project governance.
The Foundation is a separate nonprofit organization with its own programs, staff, and Board. Foundation staff carry out the organization’s day-to-day work, including software development work, advocacy, fundraising, communications, events, operations, grants, partnerships, and program management.
The Foundation Board provides governance, oversight, and strategic direction for the Foundation. The Board does not govern the FreeBSD Project, make technical decisions for FreeBSD, direct committers, or manage staff’s daily work. Instead, it approves the annual budget, helps guide the Foundation’s priorities, and ensures the organization is using its resources responsibly and in alignment with its mission.
Each group has a distinct role, but all are part of the same FreeBSD ecosystem and are working toward FreeBSD’s long-term success.
What the Foundation Board Does
The Foundation Board exists to help the organization make thoughtful, responsible decisions for the long term. It brings together people with different experiences and perspectives to help the Foundation stay focused, accountable, and connected to the broader FreeBSD ecosystem.
Board members review and approve the Foundation’s annual budget, provide input on organizational strategy, and help evaluate major priorities. They also support the Foundation’s work in areas such as fundraising, governance, sustainability, community relationships, and long-term planning.
A strong Board brings a mix of experience and perspective. This may include knowledge of FreeBSD and open source communities, nonprofit governance, finance, fundraising, legal and policy issues, business development, technology strategy, security, and organizational growth.
As the Foundation and the FreeBSD ecosystem continue to evolve, the Board considers what skills and perspectives would strengthen its ability to guide the organization. This helps ensure the Board remains well-positioned to provide thoughtful oversight and help the Foundation plan responsibly for the future.
How Board Members Are Identified and Elected
Board members are elected by the current Board at the Foundation’s annual meeting.
The process leading up to the election is intentional and ongoing. Current board members discuss the needs of the organization, consider the experience already represented on the Board, and identify areas where additional expertise or perspective may be useful.
The Board also meets with individuals who may be interested in serving. These conversations may include people from within the FreeBSD community as well as individuals outside the community who bring relevant experience that could benefit the Foundation.
The goal is not simply to fill a seat. It is to build and maintain a Board that can provide thoughtful governance, contribute useful perspectives, and help guide the Foundation in ways that benefit the long-term health of FreeBSD.
Potential board members are generally people who understand the importance of FreeBSD, care about the Foundation’s work, and are willing to take an active role in helping the organization succeed.
What Board Members Are Expected to Do
Serving on the FreeBSD Foundation Board is a volunteer role, but it carries important responsibilities.
Board members are expected to attend meetings, review materials in advance, participate in discussions, and remain engaged between meetings. They are also expected to bring their experience, judgment, and networks to the Foundation’s work when those contributions are helpful.
This may include providing feedback on strategic questions, helping think through organizational challenges, supporting fundraising efforts, making introductions, or advising staff and fellow board members on areas where they have relevant expertise.
Effective board service does not mean directing staff’s daily work. It means helping ensure the Foundation has the resources, structure, guidance, and accountability needed to carry out its work well.
Why This Matters
Good governance is not always the most visible part of the Foundation’s work, but it is essential.
The Foundation is trusted with donor funds, community expectations, and an important role within the FreeBSD ecosystem. A strong Board helps ensure the Foundation is planning responsibly, making thoughtful decisions, and remaining focused on work that benefits FreeBSD.
As the needs of the FreeBSD ecosystem continue to grow and change, the Foundation Board will continue to look for the right mix of experience, perspective, and commitment to help guide the organization forward.
We are grateful to everyone who serves or has expressed interest in serving the Foundation in this capacity. While much of this work happens behind the scenes, it plays an important role in keeping the Foundation strong, sustainable, and prepared to contribute to FreeBSD’s long-term success.
FreeBSD Community member and former Core Representative, Dave Cottlehuber, was elected to the FreeBSD Foundation Board during the Annual Meeting on June 15, 2026. We sat down with Dave to learn more about his history with FreeBSD and what he’s most looking forward to accomplishing during his tenure.
Tell us a little about yourself, and how you got involved with FreeBSD?
I’m a relative newcomer to FreeBSD. I didn’t use it at university, and I only started my UNIX experience in early 2001, with an OpenBSD 2.8 CD and poster.
I spent most of my teens and early twenties climbing mountains and skiing down them. Computers were of little interest to me at that time, but midway through a Science degree, I found my niche, and eventually started working part time at the University computer centre.
I remember a colleague eagerly rushing through with a FreeBSD CD, probably 3.something, in 1998 or 1999, but that was as close as I came.
The next decade was a move from New Zealand through France, Slovak Republic, and back to New Zealand, and in parallel, shifting from hands-on tech, into middle management, at various large corporations and telcos.
In 2010 I made an intentional decision to move away from that, and moved to working with open source software projects, and communities, in part to allow us to relocate back to Europe.
Around 2013 I actively switched to FreeBSD, and made it to my first BSDCan conference in 2016. The first people I met there were Peter Hessler from OpenBSD, Mark Linimon and Li-Wen Hsu from FreeBSD. With such friendly introductions, I was hooked!
Under Joseph Mingrone’s mentorship, I gained a ports commit bit in 2017, and became progressively more involved. In 2024, I began helping out with release engineering, under Colin Percival’s watchful eye, and in mid 2024 I also joined the FreeBSD Core team, for my first term.
This brought me into contact with a much broader range of people, within the community, the Foundation, and the wider project, and the complexities of both understanding and running such a distributed group of people.
Why are you passionate about serving on the FreeBSD Foundation Board?
The FreeBSD community was an unexpected, but very welcome, engagement later in my life.
Much of our daily commercial work is necessarily focused on delivering to shareholders and customers, and it’s both satisfying and important to do things for the long term, to contribute to the common good. I get a great deal of personal satisfaction out of helping and seeing people, and the project itself, thrive.
What excites you about our work?
The Foundation operates on a longer timescale than most of us get to work on day-to-day — funding development that wouldn’t otherwise happen, supporting infrastructure, advocacy, and the conferences that hold the community together. Bringing people and organisations together for that kind of long-term work doesn’t happen overnight, and being part of it is a unique opportunity.
What are you hoping to bring to the organization and the community through your new leadership role?
I don’t see this as a new leadership role so much as a continuation — a branch, if you will, of my existing involvement. Coming to the board directly from Core, I hope to help strengthen the connections between the Foundation, the developers, our users, and the wider community, and to keep fostering a shared sense of identity and purpose across them all.
How do you see your background and experience complementing the current board?
Helping people understand each other’s strengths and perspectives, and finding ways to be successful together as FreeBSD, is challenging work — and genuinely rewarding.
I’ve worked on a number of transition and transformation programmes over the years, both technical and people-focused, and more recently in open source community building. I’m looking to bring both a community context and an active contributor’s viewpoint to the board, and to continue working across ‘the whole project’ in the widest possible sense.
Teaching others about FreeBSD and helping it grow doesn’t require a developer background — it just takes someone willing to show up and talk about why this project matters. Whether that’s presenting at a local meetup or bringing FreeBSD into a classroom, community advocacy is one of the most effective ways we grow the project.
Is There a Local Event Where You Could Represent FreeBSD?
Is there a meetup, conference, or user group in your area where FreeBSD could use a voice? We’re always looking for community members willing to represent the project locally, whether that means giving a talk, staffing a table, or simply striking up conversations about FreeBSD. If you’re speaking about FreeBSD at an upcoming event, let us know; we can help spread the word, and ourTravel Grant program may be able to help cover the cost of getting there.
Thinking About Hosting a Table or Booth?
If you’d like to run a FreeBSD community table at an event, you don’t have to figure it out from scratch. We’ve put together a set of Community Table Guidelines covering everything from talking points and etiquette to what to bring and how to handle tricky questions, so you can focus on the conversations instead of the logistics. Reach out to marketing@freebsdfoundation.org for a copy, and don’t forget to grablogos, stickers, and other materials before you go.
Bring FreeBSD to Your Class or Club
We’re also launching a new way to connect with students directly. If you’re a student who’d like someone from the FreeBSD community to speak virtually to your class or club, you can now request a virtual speaker through our new speaker request form. Whether your group wants an introduction to FreeBSD, a walkthrough of installing it for the first time, or a conversation about careers in open source, we’ll match you with someone from the community who can join your class or meeting remotely.
Advocacy doesn’t have to be complicated. A five-minute conversation with a professor, a slide deck at a local user group, or a sticker handed out at a hackathon all move the project forward. Ready to get involved?
Request a virtual speaker, tell us about your event, or reach out to marketing@freebsdfoundation.org with questions.
Microsoft Corp. today released software updates to plug at least 570 security holes in its Windows operating systems and other software, almost triple the number of vulnerabilities the software giant fixed in its record-smashing Patch Tuesday release last month. Microsoft attributed the burgeoning patch counts to vulnerability discoveries aided by artificial intelligence.
Nearly 60 of the bugs quashed in July’s Patch Tuesday earned a “critical” severity rating, meaning miscreants or malware could use them to seize remote control over a Windows device with little or no help from the user. Microsoft also addressed three zero-day flaws, including two that are already being exploited in the wild.
Two of the zero-day weaknesses allow an attacker to elevate their user rights on a Windows system, as do approximately 250 other elevation of privilege flaws fixed this month; they include CVE-2026-56155 — an Active Directory Federation Services bug — and CVE-2026-56164, a Microsoft Sharepoint vulnerability.
CVE-2026-50661 is a security feature bypass in Windows BitLocker that could allow attackers to gain access to encrypted data if they have physical access to the device. Microsoft said this bug has been detailed publicly, but that it is not aware of any active exploitation.
In a blog post on July 9, Microsoft Executive Vice President Pavan Davuluri wrote that Windows users will notice “a higher volume of security updates included in each security release” as a result of AI aiding in the discovery of vulnerabilities.
“The pace of vulnerability discovery is changing with advances in AI making it possible to find more issues, faster, across more code, with new mechanisms that can accelerate both discovery and analysis,” Davuluri wrote.
Jack Bicer, director of vulnerability research at Action1, called attention to CVE-2026-48561, a remote code execution flaw in Microsoft Copilot (with a 9.6 CVSS threat score) that allows an unauthorized attacker to execute code over the network. Microsoft says an attacker could exploit this bug by hosting a malicious website that causes Microsoft Edge for Android to automatically send crafted prompts to Copilot when a user visits the site.
As AI advances the state of vulnerability discovery and remediation, it is also making it easier for attackers to quickly devise working exploits for known software flaws. Microsoft has long labeled security bugs using its “exploitability index,” which is Redmond’s best guess as to how likely it is that attackers will be able to figure out a reliable way to exploit a given vulnerability.
But Satnam Narang, senior staff research engineer at Tenable, argues that Microsoft’s exploitability index needs to do a better job of shifting with the machine speed of discovery. For example, Microsoft originally gave this month’s SharePoint zero-day an exploitability rating of “less likely,” although the flaw was added to CISA’s Known Exploited Vulnerabilities list on July 1.
“Anthropic’s Red Team’s own findings for known vulnerabilities (n-days) revealed how fragile this system has become, with its Mythos Preview model being able to produce proof-of-concept exploits for 13 of 14 vulnerabilities that were rated ‘Exploitation Less Likely’ or ‘Exploitation Unlikely,'” Narang said. “What this means is that our way of looking at Patch Tuesday has changed, because the exploitability index is centered around humans, not AI tools, and as these tools continue to improve, defense needs to improve alongside it.”
Chris Goettl at Ivanti observed that the record patch numbers from Microsoft come as a number of other major software makers are increasing their patch cadence, including Adobe which announced today it is moving to twice-monthly security bulletins published on the 2nd and 4th Tuesday of each month (Adobe also cited AI for accelerating their patch cycles). Cisco, Mozilla and Oracle also are shipping updates more frequently, while Google’s patch batches in June 2026 totaled more than 900 security fixes, Goettl noted.
Backing up your Windows system and/or data is always a good idea before applying operating system updates. Given the volume of patches addressed this month it may be wise for end users to wait a few days before applying these fixes. It’s not uncommon for security patches to introduce system stability issues, and those chances probably increase quite a bit with the gigantic patch count released today.
The Cybersecurity and Infrastructure Security Agency (CISA) has issued a postmortem on a recent data leak in which a contractor published dozens of internal CISA credentials — including AWS Govcloud keys — in a public GitHub repository for almost six months before being notified by KrebsOnSecurity. Experts say the gaps identified in the agency’s initial response provide important lessons that all security teams should absorb.
On May 15, 2026, the security firm GitGuardian asked for help in notifying CISA about the existence of a public GitHub repository called “Private CISA” that included 844 MB of sensitive CISA-related data. One of the exposed files, titled “importantAWStokens,” included the administrative credentials to three Amazon AWS GovCloud servers. Another file — “AWS-Workspace-Firefox-Passwords.csv” — listed plaintext usernames and passwords for dozens of internal CISA systems.
CISA quickly acknowledged our initial alert, but took more than 48 hours to invalidate the AWS keys and many other important secrets leaked in the GitHub repo. In its report on the data leak, CISA said the complexities of the agency’s systems and interconnections with federal and industry partners caused its key rotation to take longer than anticipated.
“Drawing on this experience, CISA encourages others to maintain mature and well-tested key management capabilities,” the report notes.
CISA also admitted it can do better when it comes to responding to security incident notifications from external parties. The postmortem stresses that clear and distinct reporting channels are essential to ensure that incidents affecting the organization itself are handled differently from those involving its products or customers.
“In CISA’s case, these channels were not well defined, leading the security researcher to try multiple avenues – including emailing the contractor, submitting through CISA’s vulnerability disclosure platform (which is intended for vulnerabilities impacting the broader cybersecurity community), and ultimately involving a reporter,” reads the analysis written by Preston Werntz and Brad Libbey, the acting chief information officer and acting chief information security officer at CISA, respectively.
CISA said it is refining its reporting channels to make them easier and faster for researchers. “Additionally, while many researchers rely on the security.txt file, organizations can ensure clarity by publishing reporting instructions in multiple prominent locations,” the CISA authors wrote.
Guillaume Valadon, the GitGuardian researcher who first contacted KrebsOnSecurity about the exposed CISA credentials, said CISA ignored nine automated alerts about the exposed credentials prior to our notification on May 15. Valadon’s company constantly scans public code repositories at GitHub and elsewhere for exposed secrets, automatically alerting the offending accounts of any apparent sensitive data exposures.
“Letting nine notification emails go unanswered is how a one-day incident becomes a six-month exposure,” Valadon wrote in an analysis of CISA’s report. “Make it trivial to report a leak about you, not just about your products. The person reporting a leak to you is not the threat. Publish a security.txt, but do not stop there. Put reporting instructions in several prominent places, and make sure a report about your own infrastructure does not land in a product-bug queue.”
The report’s authors also emphasized the importance of continuously scanning public code repositories like GitHub for exposed secrets, and said CISA has since rotated all secrets and created an action plan to improve management of developer secrets and to better monitor for them going forward.
The report notes that while CISA had developed a playbook for responding to cybersecurity incidents, that playbook somehow didn’t include what to do in situations involving GitHub or other cloud services. Valadon said the report validates the need to scan continuously — not just quarterly — for exposed secrets.
“The Private-CISA repository sat public for six months,” Valadon wrote. “Continuous monitoring of public GitHub surfaced it. Comprehensive internal scanning could have caught the plaintext passwords and committed backups long before they left the building.”
CISA gave itself passing grades on several areas of security preparedness that it said helped the agency gauge the scope and impact of the exposed secrets, including enhanced logging capabilities, and the adoption of zero-trust principles in both its production and development systems. CISA said those detailed logs allowed it to show that no customer or mission data was exposed, and that the leaked credentials were not used outside of CISA’s environments. The agency said the contractor who exposed the secrets had their system access revoked.
Valadon reckons the biggest takeaway is the CISA postmortem itself, and praised the agency for being transparent about what worked and what didn’t.
“To my knowledge, it is also the first time a national cybersecurity agency has publicly advocated for secrets scanning and for simplifying relations with security researchers,” Valadon wrote. “That is exactly the incident communication we should expect from every organization.”
The Valuable News weekly series is dedicated to provide summary about news, articles and other interesting stuff mostly but not always related to the UNIX/BSD/Linux systems. Whenever I stumble upon something worth mentioning on the Internet I just put it here.
Today the amount information that we get using various information streams is at massive overload. Thus one needs to focus only on what is important without the need to grep(1) the Internet everyday. Hence the idea of providing such information ‘bulk’ as I already do that grep(1).
The Usual Suspects section at the end is permanent and have links to other sites with interesting UNIX/BSD/Linux news.
Past releases are available at the dedicated NEWS page.
Die vierte Spielrunde ging zu Ende. Zeit für eine kurze Bilanz. Die Teilnahme war stabil, die Kämpfe um die vorderen Plätze bis zuletzt eng. Am Ende setzte sich M0n1y durch und sicherte sich den ersten Platz.
Die Top 3 sowie alle weiteren Platzierungen sind in der Grafik zu sehen. Wer genau wie viele Punkte gesammelt hat und wie die Bewegungen in den letzten Tagen aussahen, lässt sich dort nachvollziehen.
Der Start von MMO-2044 V2 steht in ein paar Wochen bevor. Die Grundmechanik bleibt, aber es gibt einige Anpassungen unter der Haube. Die wichtigsten Änderungen betreffen die Ressourcenlogistik und die Flottenbewegungen. Wer in der letzten Runde mit Spielmechaniken zu kämpfen hatte, wird einige Verbesserungen bemerken.
Mehr Details gibt es mit dem Starttermin.
Bis dahin bleibt die aktuelle Instanz noch online, für alle, die die letzten Punkte sichern oder einfach nur noch ein paar Runden drehen wollen.
Vielen Dank an alle Teilnehmer und auch danke für die Feedbacks!
Today I will share how to install and setup a GitLab server on FreeBSD. Most people just use Microslopft GitHub these days but this approach has one big drawback – its cloud only solution. When it comes to on premise solutions there are GitLab and there is also Gitea. GitLab is closest to what GitHub provides while Gitea is very light and smaller brother trying to achieve the same goals by doing less. Good to have alternatives.
To expand the disk/partition/pool this is the guide You are looking for – Expand GELI Encrypted Bhyve VM ZFS Disk – just omit the GELI part as its not used here.
root@gitlab:~ # su -l git -c "cd /usr/local/www/gitlab \
&& env DISABLE_DATABASE_ENVIRONMENT_CHECK=1 \
rake gitlab:setup RAILS_ENV=production \
GITLAB_ROOT_PASSWORD=password"
(...)
Do you want to continue (yes/no)? yes
(...)
Could not create the default administrator account:
--> Password must not contain commonly used combinations of words and letters
I wanted this guide to be a generic setup – with ‘must to change’ password as password but GitLab knows better – lets cope with that.
Lets try something more sophisticated:
root@gitlab:~ # su -l git -c "cd /usr/local/www/gitlab \
&& env DISABLE_DATABASE_ENVIRONMENT_CHECK=1 \
rake gitlab:setup RAILS_ENV=production \
GITLAB_ROOT_PASSWORD=GtFO/wTh!sBu112!t"
(...)
Do you want to continue (yes/no)? yes
Dropped database 'gitlabhq_production'
Created database 'gitlabhq_production'
== Seed from /usr/local/www/gitlab/db/fixtures/production/001_application_settings.rb
Creating the default ApplicationSetting record.
== /usr/local/www/gitlab/db/fixtures/production/001_application_settings.rb took 0.70 seconds
== Seed from /usr/local/www/gitlab/db/fixtures/production/002_default_organization.rb
OK
== /usr/local/www/gitlab/db/fixtures/production/002_default_organization.rb took 0.08 seconds
== Seed from /usr/local/www/gitlab/db/fixtures/production/003_admin.rb
Administrator account created:
login: root
password: ******
== /usr/local/www/gitlab/db/fixtures/production/003_admin.rb took 2.61 seconds
== Seed from /usr/local/www/gitlab/db/fixtures/production/010_settings.rb
Saved CI JWT signing key
Saved CI Job Token signing key
== /usr/local/www/gitlab/db/fixtures/production/010_settings.rb took 0.67 seconds
== Seeding took 4.06 seconds
root@gitlab:~ # echo $?
0
root@gitlab:~ # su -l git -c "cd /usr/local/www/gitlab && rake gitlab:env:info RAILS_ENV=production"
you have mail
System information
System:
Current User: git
Using RVM: no
Ruby Version: 3.4.9
Gem Version: 4.0.15
Bundler Version:4.0.15
Rake Version: 13.4.2
Redis Version: 8.8.0
Sidekiq Version:7.3.9
Go Version: unknown
GitLab information
Version: 19.1.1
Revision: Unknown
Directory: /usr/local/www/gitlab
DB Adapter: PostgreSQL
DB Version: 18.4
URL: http://localhost
HTTP Clone URL: http://localhost/some-group/some-project.git
SSH Clone URL: git@localhost:some-group/some-project.git
Using LDAP: no
Using Omniauth: yes
Omniauth Providers:
GitLab Shell
Version: 14.54.0
Repository storages:
- default: unix:/usr/local/www/gitlab/tmp/sockets/private/gitaly.socket
GitLab Shell path: /usr/local/share/gitlab-shell
(...)
Remove superuser rights from PostgreSQL database user.
root@gitlab:~ # psql -d template1 -U postgres -c "ALTER USER git WITH NOSUPERUSER;"
… and enable and start GitLab service.
root@gitlab:~ # service gitlab enable
root@gitlab:~ # service gitlab start
GitLab Registry Key missing. Generating...
(...)
Starting GitLab web server (puma)
Starting GitLab Sidekiq
Starting GitLab Workhorse
Starting Gitaly
(...)
Started in 53s.
The GitLab web server with pid 70182 is running.
The GitLab Sidekiq job dispatcher with pid 72791 is running.
The GitLab Workhorse with pid 74932 is running.
Gitaly with pid 76120 is running.
GitLab and all its components are up and running.
Nginx
Site Configuration – include provided configuration in your Nginx configuration.
root@gitlab:~ # vi /usr/local/etc/nginx/nginx.conf
Within 'http' configuration block add this:
include /usr/local/www/gitlab/lib/support/nginx/gitlab;
root@gitlab:~ # nginx -t
nginx: the configuration file /usr/local/etc/nginx/nginx.conf syntax is ok
nginx: configuration file /usr/local/etc/nginx/nginx.conf test is successful
This above is the message You expect to see.
Next enable and start Nginx server.
root@gitlab:~ # service nginx enable
root@gitlab:~ # service nginx restart
A cybersecurity startup dangling millions of dollars to acquire zero-day security vulnerabilities in popular software is run by a pair of far-right conspiracy theorists and convicted felons whose most recent ventures included fake intelligence companies and a now-defunct AI-based lobbying platform they operated under assumed names.
The X/Twitter account IRIS C2 (@C2IRIS) has gained more than 4,000 followers since its creation in January 2025, posting frequently about security vulnerabilities, AI and software exploits. IRIS C2 says it is a company in McLean, Va. that sells offensive cybersecurity capabilities.
The IRIS C2 website dangles the possibility of million-dollar payouts for exploits to attract talent.
“Our business model is this,” reads a pinned post on top of the IRIS C2 account on X. “Attract the very best vulnerability researchers and exploit developers in the world to join our company. This mostly revolves around junior engineers with raw talent/extremely high IQ. We don’t care if they have a college degree/industry experience.”
The website linked in that profile — irisc2[.]com — says the company is hiring for a number of open positions, and a recent post on its LinkedIn page enthuses about an overwhelming number of applications from potential employees. The website claims IRIS C2 is in the business of acquiring “zero-day exploits, individual primitives, partial chains, and full capabilities across all major platforms. Payouts range from $10,000 to $7 million depending on target, reliability, and operational value.”
The government contracting portal g2exchange.comreports that irisc2[.]com is operated by a business based in Virginia called Calvexa Group LLC. The “contact” link on the website for Calvexa Group — calvexagroup[.]com — forwards visitors to irisc2[.]com. G2Exchange shows that while Calvexa Group LLC is registered as a federal contractor, it does not appear to be working on any direct government contracts.
A search on the Arlington, Va. address listed in the incorporation records for Calvexa Group LLC finds the property is occupied by Jack Burkman, the 60-year-old founder and managing partner of the lobbying firm Burkman & Associates. When approached with questions about IRIS C2, Burkman referred further inquiries to his longtime associate, 28-year-old Jacob Wohl.
Jack Burkman (left) and Jacob Wohl, at a press conference in August 2020. Image: Wikipedia.
Burkman and Wohl have a storied history of creating fake intelligence companies and using them to spread false claims about and frame public figures, including fabricated sexual assault claims against then FBI director Robert Mueller, and Pete Buttigieg, then mayor of South Bend, Indiana and a Democratic candidate for the presidency. In 2019, Burkman and Wohl held press conferences falsely alleging extramarital affairs by Sen. Elizabeth Warren (D-Mass.) and then-2020 presidential candidate Kamala Harris.
In the wake of the 2020 presidential election, Wohl and Burkman were prosecuted by multiple U.S. states for making thousands of robocalls to residents of battleground states and disseminating false claims about mail-in ballots. They were indicted in Cleveland on 15 felony counts of orchestrating a robocall scheme aimed at suppressing the black vote in Detroit, and were sentenced in late 2025 to probation after their appeals to dismiss the charges were rejected.
In 2022, Wohl and Burkman both pleaded guilty to a single felony charge of telecommunications fraud in Ohio, and sentenced to a fine, probation, and community service. In March 2023, a judge in a New York civil case ruled that Wohl and Burkman had violated federal and state civil rights laws, and the two agreed to pay a $1 million settlement.
In June 2023, the Federal Communications Commission (FCC) imposed a $5.1 million fine against Wohl and Burkman for their robocall campaigns, at the time the largest fine ever sought by the FCC under the Telephone Consumer Protection Act.
Jacob “Jay” Wohl’s GitHub account.
By the age of 17, Wohl had started multiple investment firms, and cultivated the nickname “Wohl of Wall Street” after appearing on Fox News in 2015 to discuss his new hedge funds. In 2017, the Arizona Corporation Commission charged Wohl and his investment funds with 14 counts of securities fraud, and ordered him to pay $35,000 in restitution. In 2019, Wohl pleaded guilty in California to four felony counts of selling unregistered securities and was sentenced to two years of probation.
The market for previously unknown security vulnerabilities has always been populated by a colorful mix of researchers, academics, charlatans, clout-chasers and people actively involved in cybercrime communities. But the market for selling offensive security services to the U.S. government tends to be far more circumspect. Plenty of government contractors recruit vulnerability researchers and pay for the exclusive rights to novel software exploits, yet none of them do so quite as brazenly and openly as IRIS C2.
Recent posts from the Twitter/X account IRISC2 (@c2iris).
Indeed, KrebsOnSecurity was unaware of IRIS C2 until last month, when an attendee at a regional cybersecurity conference shared that Wohl and Calvexa Group were pestering people at the conference about selling their vulnerability research.
In an interview with KrebsOnSecurity, Wohl said Mr. Burkman was not involved in the day-to-day operations of IRIS C2. Wohl shared that IRIS C2 originally began as a penetration testing company, but shifted its focus recently to selling phone-hacking services to the government. Several times throughout the interview, Mr. Wohl mentioned working on federal government contracts, but when pressed for specifics said he was not at liberty to speak publicly about them.
Mr. Wohl said he does not have any formal education or training in computer science or information security, and that most of his knowledge on the matter is self-taught.
“I know more about tech than anyone,” Wohl bragged. “My background has always been extremely technical, and I’ve always been deeply into tech. People know me as someone who is able to create spectacularly exquisite capabilities that would make your head spin.”
Wohl said security researchers bring the company unique vulnerability findings “on a regular basis,” but that in many cases those findings are preliminary and not fully fleshed-out.
“Let’s say someone finds a flaw in a media decoder on a phone,” Wohl said. “A lot of times what we receive is an exploit primitive, where the idea is there but the [execution] needs work. You need that exploit to be stable and reliable, and that’s what we do.”
Wohl claims IRIS C2 has approximately 40 employees, although he said none of them are allowed to list their employment on LinkedIn for operational security reasons. In May, the author of the IRIS C2 account on X said that his girlfriend had no idea what he did for a living. But if IRIS C2 has any other employees, they may be similarly unaware of Mr. Wohl’s history of outright fabrications — or even his real name.
In September 2024, Politicoreported that Burkman and Wohl were bragging about big companies supposedly buying services from their now-defunct company LobbyMatic, which claimed to use artificial intelligence to assist in political lobbying efforts. However, Politico found the pair were running the company using pseudonyms, with Wohl reportedly adopting the name “Jay Klein” and Burkman using the moniker “Bill Sanders.” Politico reported that two of the former LobbyMatic employees resigned after learning of their true identities, while other employees only learned after they had left the company.
Update, July 9, 9:44 a.m. ET: Several readers pointed our attention to a March 31 publication from journalist Molly White, which reported that Burkman and Wohl were paid a $300,000 retainer by a Canadian cryptocurrency fraudster wanted by the United States and several other countries for allegedly stealing $65 million from the crypto platforms KyberSwap and Indexed Finance. According to that report, the two were hired to pursue a “presidential pardon to avert a miscarriage of justice” on behalf of the accused hacker, who has not yet been convicted.
One of my FreeBSD boxes runs `bsnmpd`, the base system SNMP daemon.
The machine is on 15.0-p2, and the daemon kept growing until the kernel ran out of patience and OOM-killed it.
That is not a good feature for a daemon.
I could have just added a cron job to restart it and called it a day.
But a leak that kills a long-running daemon is exactly the kind of thing I like to chase, and I already had a tool for it.
The Federal Bureau of Investigation (FBI) said today it worked with industry partners to seize hundreds of domains associated with NetNut, a sprawling residential proxy service operated by the publicly-traded Israeli company Alarum Technologies [NASDAQ: ALAR]. The action comes roughly two weeks after KrebsOnSecurity published findings from multiple security firms connecting NetNut to the Popa botnet, a collection of at least two million devices that have been compromised by malicious software with little or no consent from victims.
The NetNut homepage today was replaced by this seizure banner from the FBI.
On June 19, three different security firms issued similar findings: That NetNut is a residential proxy network which populates a botnet called Popa, and distributes software for devices commonly found in homes, such as smart TVs and streaming boxes. NetNut’s software turns those systems into always-on residential proxy nodes that are rented to others, who predominantly use them to relay abusive and intrusive Internet traffic, such as mass content scraping, advertising fraud, and account takeover activity.
Earlier today, NetNut’s homepage was replaced with a seizure notice from the FBI and the Internal Revenue Service Criminal Investigation division. The seizure notice thanked Google, Lumen, Shadowserver and other industry partners for their help in dismantling hundreds of domains tied to the Popa botnet, which experts say has long been synonymous with NetNut’s residential proxy infrastructure.
In a blog post published today, the GoogleThreat Intelligence Group (GTIG) said NetNut’s proxy network is widely resold and white-labeled by a number of third-party proxy providers, and that its services are heavily sought out by cybercriminals seeking to obfuscate the source of their malicious traffic. The GTIG said that in a single week during June 2026, they observed 316 distinct clusters of threat actors using suspected NetNut exit nodes, including cybercriminal and espionage groups.
“These bad actors can use NetNut to mask their origin IP address when accessing victim environments, accessing their own infrastructure, and conducting password spray attacks,” Google’s GTIG wrote. “Furthermore, when a consumer device becomes an exit node, unauthorized network traffic passes through it. This means bad actors can access other private devices on the same home network, effectively exposing them to Internet threats.”
Google said it disabled Google accounts and services used by NetNut for malware command and control, and that it shared technical intelligence on NetNut’s software development kits (SDKs) and backend infrastructure with platform providers, law enforcement and research firms. The company also disabled apps known to bundle NetNut’s various SDKs.
Omer Weiss, legal counsel for NetNut parent Alarum Technologies, said the company was aware of the FBI seizure and cooperating with investigators.
“Alarum takes this matter seriously and will fully cooperate with law enforcement to ensure any misuse of its infrastructure is thoroughly investigated and those responsible are held to account,” Weiss said in a written statement.
Benjamin Brundage is founder of the proxy tracking service Synthient, one of the companies that published evidence last month linking the Popa botnet to NetNut and Alarum Technologies. Brundage said the domain seizures appear to have disrupted both the Popa botnet and the NetNut proxy network that rides on top of it.
Brundage said NetNut’s apparent demise is likely to be a great disadvantage for the cybercrime community, which was already reeling from legal actions by Google earlier this year that seized infrastructure for NetNut’s biggest competitor — IPIDEA.
“I think this takedown is going to have a big impact, because NetNut gained significant popularity after the IPIDEA takedown,” he said. “Also NetNut has been incredibly common among resellers, and they were on par with IPIDEA in terms of their daily traffic, quality, size, price per gigabyte, all of it.”
NetNut’s infrastructure, in a nutshell. Image: Black Lotus Labs, Lumen.
The NetNut and Popa botnet takedown may have another added benefit, Brundage said: Lessening the impact of large distributed denial-of-service botnets that have been built on the backs of poorly configured residential proxy services. In January, Synthient revealed how cybercriminals had built the world’s largest DDoS botnet (Kimwolf) by tunneling through IPIDEA proxy connections into the local networks of TV box owners, and infecting other Android-based devices behind the victim’s firewall.
While many of the bigger proxy providers took steps to block this activity, resellers of the major proxy networks have been far slower to respond to the threat, Brundage said.
“In terms of all these TV box devices getting compromised from the proxy network, it will have an impact on the DDoS botnets out there,” he said.
For its part, Google reckons today’s actions have caused “significant degradation to NetNut’s proxy network and its business operations, reducing the available pool of devices for the proxy operator by millions.” But the company warns that proxy networks can rebuild themselves by effectively reselling other proxy services, as IPIDEA has done over the past few months.
“Google has high confidence that many popular residential proxy brands are in fact whitelabeling the NetNut botnet,” the GTIG report concludes. “While we expect this disruption to have a larger ripple effect across the residential proxy ecosystem, observations after the disruption of IPIDEA proved that individual networks can appear resilient. What we have observed is that when faced with the degradation of their own botnet, proxy operators begin buying capacity from their competitors, effectively becoming a reseller. We recognize that creating a lasting disruption in this fluid ecosystem means we must scale our efforts to target the infrastructure of several interconnected providers.”
As KrebsOnSecurity has warned repeatedly, most of the no-name TV streaming boxes for sale on the major e-commerce websites either come pre-installed with residential proxy software, or require the installation of proxy SDKs in order to use the device for its stated purpose (streaming pirated movies, sporting events and TV shows). Google’s advice here is sound: When it comes to TV boxes, stick to name brands from reputable manufacturers, and then be sparing and judicious with any apps you choose to install.
The sketchy TV boxes that are being commandeered by the Popa botnet and other threats all come with or require the user to install unofficial Android operating systems that do not operate within the confines of Google’s Official Play Protect store. Google says consumers can confirm whether or not a device is built with the official Android TV OS and Play Protect certification by following these instructions.
Even people without TV streaming boxes can find their smart TVs enrolled in residential proxy networks, just by installing one of thousands of apps available for download on Samsung and LG smart TVs. In a report released last month, the proxy tracking company Spur found 42 percent of apps available for download via the webOS operating system on LG smart TVs include SDKs that turn one’s television into an always-on residential proxy node. More than a quarter of the apps made for Samsung’s Tizen operating system had similar residential proxy components, Spur found.
Image: Spur.us.
Update, 4:24 p.m. ET: Included a statement shared post-publication from an attorney representing NetNut parent Alarum Technologies.
Update, July 8, 2:34 p.m. ET: The website for Alarum Technologies — alarum[.]io — now also features a seizure notice from the FBI. The company’s stock has taken a beating since the FBI action, and is currently trading at $2.62 a share, a roughly 67 percent decline over the past week.
Over the weekend, some branches fell on a neighbor’s power service line. They still had power, but the branches had to be removed. That removal occurred this morning. I saw the trucks at about 6:45 AM as I walked past. I suspected I might lose power, and I did. This post records the shutdown and power on times/sequences. I might find this useful should I need to reevaluate the power-outage procedures.
My thought: Perhaps just shutdown the big servers, but keep the gateway, wireless access points, and switches running. The goal being: shutdown the heavy stuff, keep the light stuff going, perhaps for an hour or so. The actual time, I don’t know because I’ve never tried. I could judge that based on power consumption by those units… the information is all there in the PDU graphs…
In this post:
FreeBSD 15.0
nut-2.8.5_1
gw01
/var/log/messages shows:
Jul 6 11:09:53 gw01 upsmon[3974]: UPS heartbeat on line power
Jul 6 11:09:58 gw01 upsmon[3974]: UPS ups04 on battery
Jul 6 11:14:53 gw01 upsmon[3974]: UPS heartbeat on battery
Jul 6 11:17:38 gw01 upsmon[3974]: UPS ups04 battery is low
Jul 6 11:17:38 gw01 upsmon[3974]: Too few UPS(es) are healthy (0<1), initiating forced shutdown
Jul 6 11:17:38 gw01 upsmon[3974]: UPS ups04: forced shutdown in progress
Jul 6 11:17:38 gw01 upsmon[3974]: UPS heartbeat: forced shutdown in progress
Jul 6 11:17:38 gw01 upsmon[3974]: Shutdown initiated; primary system is waiting for secondaries to log out or time out
Jul 6 11:17:45 gw01 upsmon[3974]: Executing automatic power-fail shutdown
Jul 6 11:17:45 gw01 upsmon[3974]: Auto logout and shutdown proceeding
Jul 6 11:35:49 gw01 syslogd: kernel boot file is /boot/kernel/kernel
Jul 6 11:35:49 gw01 kernel: ---<<BOOT>>---
r730-01
Logs show:
Jul 6 11:09:35 r730-01 upsmon[2468]: UPS heartbeat on line power
Jul 6 11:10:00 r730-01 upsmon[2468]: UPS ups04@gw01.int.unixathome.org on battery
Jul 6 11:14:35 r730-01 upsmon[2468]: UPS heartbeat on battery
Jul 6 11:17:35 r730-01 upsmon[2468]: UPS ups04@gw01.int.unixathome.org battery is low
Jul 6 11:17:40 r730-01 upsmon[2468]: UPS ups04@gw01.int.unixathome.org: forced shutdown in progress
Jul 6 11:17:40 r730-01 upsmon[2468]: Too few UPS(es) are healthy (0<1), initiating forced shutdown
Jul 6 11:17:40 r730-01 upsmon[2468]: UPS heartbeat: forced shutdown in progress
Jul 6 11:17:40 r730-01 upsmon[2468]: Executing automatic power-fail shutdown
Jul 6 11:17:40 r730-01 upsmon[2468]: Auto logout and shutdown proceeding
Jul 6 11:17:45 r730-01 upsmon[2468]: doshutdown: call parent pipe for shutdown (async)
Jul 6 11:17:45 r730-01 upsmon[2468]: Exiting upsmon program after initiating shutdown
Jul 6 11:17:45 r730-01 upsmon[2466]: upsmon parent: Unable to call shutdown command: /sbin/shutdown
Jul 6 11:17:45 r730-01 upsmon[2466]: upsmon parent: Exiting after trying to call (256) shutdown command: /sbin/shutdown
Jul 6 11:42:00 r730-01 syslogd: kernel boot file is /boot/kernel/kernel
Jul 6 11:42:00 r730-01 kernel: ---<<BOOT>>---
r730-03
Logs show:
Jul 6 11:08:59 r730-03 upsmon[2142]: UPS heartbeat on line power
Jul 6 11:09:59 r730-03 upsmon[2142]: UPS ups04@gw01.int.unixathome.org on battery
Jul 6 11:13:59 r730-03 upsmon[2142]: UPS heartbeat on battery
Jul 6 11:17:39 r730-03 upsmon[2142]: UPS ups04@gw01.int.unixathome.org: forced shutdown in progress
Jul 6 11:17:39 r730-03 upsmon[2142]: UPS ups04@gw01.int.unixathome.org battery is low
Jul 6 11:17:39 r730-03 upsmon[2142]: Too few UPS(es) are healthy (0<1), initiating forced shutdown
Jul 6 11:17:39 r730-03 upsmon[2142]: UPS heartbeat: forced shutdown in progress
Jul 6 11:17:39 r730-03 upsmon[2142]: Executing automatic power-fail shutdown
Jul 6 11:17:39 r730-03 upsmon[2142]: Auto logout and shutdown proceeding
Jul 6 11:17:44 r730-03 upsmon[2142]: doshutdown: call parent pipe for shutdown (async)
Jul 6 11:17:44 r730-03 upsmon[2142]: Exiting upsmon program after initiating shutdown
Jul 6 11:17:44 r730-03 upsmon[2140]: upsmon parent: Unable to call shutdown command: /sbin/shutdown
Jul 6 11:17:44 r730-03 upsmon[2140]: upsmon parent: Exiting after trying to call (256) shutdown command: /sbin/shutdown
Jul 6 11:37:26 r730-03 syslogd: kernel boot file is /boot/kernel/kernel
Jul 6 11:37:26 r730-03 kernel: ---<<BOOT>>---
Summary
This is an overview of the shutdowns.
Host all get notice of on batter at about 11:09:59
At 11:17:38, nut on gw01 decides it’s low battery time
A forced shutdown in progress appears at the same time
r730-03 gets told that at 11:17:39
11:17:39 r730-03 upsmon[2142]: UPS heartbeat: forced shutdown in progress
r730-01 gets that message at 11:17:40
11:17:38 gw01 upsmon[3974]: UPS heartbeat: forced shutdown in progress
11:17:38 gw01 upsmon[3974]: Shutdown initiated; primary system is waiting for secondaries to log out or time out
11:17:40 r730-01 upsmon[2468]: UPS heartbeat: forced shutdown in progress
Jun 29 17:58:06 r730-01 shutdown[72325]: reboot by dvl:
Jun 29 17:58:06 r730-01 root[72379]: shutting down jail stage-nginx01
Jun 29 17:58:07 r730-01 root[72634]: jail stage-nginx01 has shut down
Jun 29 17:58:08 r730-01 root[72679]: shutting down jail test-nginx01
Jun 29 17:58:08 r730-01 kernel: test-nginx01
Jun 29 17:58:08 r730-01 root[72920]: jail test-nginx01 has shut down
Jun 29 17:58:10 r730-01 root[73043]: shutting down jail dvl-nginx01
Jun 29 17:58:10 r730-01 kernel: dvl-nginx01
Jun 29 17:58:10 r730-01 root[73280]: jail dvl-nginx01 has shut down
Jun 29 17:58:11 r730-01 root[73380]: shutting down jail dev-nginx01
Jun 29 17:58:11 r730-01 kernel: dev-nginx01
Jun 29 17:58:21 r730-01 root[73986]: jail dev-nginx01 has shut down
None of those jail shutdown messages appear during power-outage related shutdown.
The Valuable News weekly series is dedicated to provide summary about news, articles and other interesting stuff mostly but not always related to the UNIX/BSD/Linux systems. Whenever I stumble upon something worth mentioning on the Internet I just put it here.
Today the amount information that we get using various information streams is at massive overload. Thus one needs to focus only on what is important without the need to grep(1) the Internet everyday. Hence the idea of providing such information ‘bulk’ as I already do that grep(1).
The Usual Suspects section at the end is permanent and have links to other sites with interesting UNIX/BSD/Linux news.
Past releases are available at the dedicated NEWS page.
This morning I noticed this in the logs after doing some pkg upgrade. I was mainly updating openvpn, but in that operation, fail2ban was removed (because I went from python312 to python314). I noticed it missing on one host:
Can't exec "/usr/local/bin/fail2ban-client": No such file or directory at /usr/local/etc/snmp/fail2ban line 116.
I ran this grep to verify fail2ban had been removed from another host:
[12:31 r730-01 dvl ~] % zpool status
pool: data01
state: ONLINE
scan: scrub repaired 0B in 00:00:07 with 0 errors on Thu Jul 2 03:48:55 2026
config:
NAME STATE READ WRITE CKSUM
data01 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gpt/Y7P0A022TEVE ONLINE 0 0 0
gpt/Y7P0A02ATEVE ONLINE 0 0 0
gpt/Y7P0A02DTEVE ONLINE 0 0 0
gpt/Y7P0A02GTEVE ONLINE 0 0 0
gpt/Y7P0A02LTEVE ONLINE 0 0 0
gpt/Y7P0A02MTEVE ONLINE 0 0 0
gpt/Y7P0A02QTEVE ONLINE 0 0 0
gpt/Y7P0A033TEVE ONLINE 0 0 0
errors: No known data errors
pool: data02
state: ONLINE
scan: scrub repaired 0B in 00:03:59 with 0 errors on Thu Jul 2 03:52:59 2026
config:
NAME STATE READ WRITE CKSUM
data02 ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gpt/S6WSNJ0T208743F ONLINE 0 0 0
gpt/S6WSNJ0T207774T ONLINE 0 0 0
errors: No known data errors
pool: data03
state: ONLINE
scan: scrub repaired 0B in 01:16:19 with 0 errors on Thu Jul 2 05:05:31 2026
config:
NAME STATE READ WRITE CKSUM
data03 ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gpt/WD_22492H800867 ONLINE 0 0 0
gpt/WD_230151801284 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
gpt/WD_230151801478 ONLINE 0 0 0
gpt/WD_230151800473 ONLINE 0 0 0
errors: No known data errors
pool: data04
state: DEGRADED
status: One or more devices have been removed.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Online the device using zpool online' or replace the device with
'zpool replace'.
scan: scrub repaired 0B in 01:11:17 with 0 errors on Thu Jul 2 05:00:37 2026
config:
NAME STATE READ WRITE CKSUM
data04 DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
gpt/S7KGNU0Y722875X ONLINE 0 0 0
gpt/S7KGNU0Y915666E ONLINE 0 0 0
gpt/S7KGNU0Y912937J ONLINE 0 0 0
gpt/S7KGNU0Y912955D REMOVED 0 0 0
gpt/S7U8NJ0Y716854P ONLINE 0 0 0
gpt/S7U8NJ0Y716801F ONLINE 0 0 0
gpt/S757NS0Y700758M ONLINE 0 0 0
gpt/S757NS0Y700760R ONLINE 0 0 0
errors: No known data errors
pool: zroot
state: ONLINE
status: Some supported and requested features are not enabled on the pool.
The pool can still be used, but some features are unavailable.
action: Enable all features using 'zpool upgrade'. Once this is done,
the pool may no longer be accessible by software that does not support
the features. See zpool-features(7) for details.
scan: scrub repaired 0B in 00:00:53 with 0 errors on Thu Jul 2 03:50:16 2026
config:
NAME STATE READ WRITE CKSUM
zroot ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gpt/zfs0_20170718AA0000185556 ONLINE 0 0 0
gpt/zfs1_20170719AA1178164201 ONLINE 0 0 0
errors: No known data errors
Then I checked Nagios – it had found the same issue. I hadn’t check Nagios before today. Oh oh.
I went to LibreNMS to see if there was any trending information about that drive. It was not found. I suspect when it dropped out, LibreNMS also dropped it. If that’s the case, that’s not helpful.
Let’s try a reboot.
After a reboot, that drive (S7KGNU0Y912955D) was not found. My next idea: open up the case and reseat that device.
I’m hoping that device is not dead. It went into service 7 months ago and priced have jumped more than slightly lately.
When I checked another device:
[13:16 r730-01 dvl ~] % sudo smartctl -a /dev/nvme4
smartctl 7.5 2025-04-30 r5714 [FreeBSD 15.0-RELEASE-p11 amd64] (local build)
Copyright (C) 2002-25, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: Samsung SSD 990 EVO Plus 4TB
...
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 1%
Data Units Read: 76,836,586 [39.3 TB]
Data Units Written: 47,333,046 [24.2 TB]
Host Read Commands: 2,617,490,888
Host Write Commands: 1,200,934,619
Controller Busy Time: 8,225
Power Cycles: 23
Power On Hours: 6,562
...
That usage level is not outrageous. All units in this zpool should be more-or-less identically used.
Drive is not dead
I powered off the host, and pulled out the ASUS Hyper M.2 X16 Gen 4 card. I move the NVMe card in question to a portable carrier. I hooked that up to my Macbook. It was identified as a “Samsung SSD 990 PRO 4TB” – that tells me it’s not completely dead.
bsdimp suggested I hook that up to a FreeBSD box.
While monitoring /var/log/messages, I did just not. Nothing. :(
I tried another USB port; nothing. I then tried a USB port on the back of the host:
[15:03 r730-03 dvl ~] % sudo smartctl -a /dev/da8
smartctl 7.5 2025-04-30 r5714 [FreeBSD 15.0-RELEASE-p11 amd64] (local build)
Copyright (C) 2002-25, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: Samsung SSD 990 PRO 4TB
Serial Number: S7KGNU0Y912955D
Firmware Version: 4B2QJXD7
PCI Vendor/Subsystem ID: 0x144d
IEEE OUI Identifier: 0x002538
Total NVM Capacity: 4,000,787,030,016 [4.00 TB]
Unallocated NVM Capacity: 0
Controller ID: 1
NVMe Version: 2.0
Number of Namespaces: 1
Namespace 1 Size/Capacity: 4,000,787,030,016 [4.00 TB]
Namespace 1 Utilization: 3,057,326,026,752 [3.05 TB]
Namespace 1 Formatted LBA Size: 512
Namespace 1 IEEE EUI-64: 002538 4951a0eec6
Local Time is: Thu Jul 2 15:03:56 2026 UTC
Firmware Updates (0x16): 3 Slots, no Reset required
Optional Admin Commands (0x0017): Security Format Frmw_DL Self_Test
Optional NVM Commands (0x0055): Comp DS_Mngmt Sav/Sel_Feat Timestmp
Log Page Attributes (0x2f): S/H_per_NS Cmd_Eff_Lg Ext_Get_Lg Telmtry_Lg Log0_FISE_MI
Maximum Data Transfer Size: 512 Pages
Warning Comp. Temp. Threshold: 82 Celsius
Critical Comp. Temp. Threshold: 85 Celsius
Supported Power States
St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat
0 + 9.39W - - 0 0 0 0 0 0
1 + 9.39W - - 1 1 1 1 0 0
2 + 9.39W - - 2 2 2 2 0 0
3 - 0.0400W - - 3 3 3 3 4200 2700
4 - 0.0050W - - 4 4 4 4 500 21800
Supported LBA Sizes (NSID 0x1)
Id Fmt Data Metadt Rel_Perf
0 + 512 0 0
=== START OF SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART/Health Information (NVMe Log 0x02, NSID 0xffffffff)
Critical Warning: 0x00
Temperature: 34 Celsius
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 0%
Data Units Read: 56,743,286 [29.0 TB]
Data Units Written: 11,391,387 [5.83 TB]
Host Read Commands: 2,383,774,544
Host Write Commands: 425,045,375
Controller Busy Time: 802
Power Cycles: 21
Power On Hours: 5,614
Unsafe Shutdowns: 10
Media and Data Integrity Errors: 0
Error Information Log Entries: 0
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Temperature Sensor 1: 34 Celsius
Temperature Sensor 2: 36 Celsius
Warning: NVMe Get Log truncated to 0x200 bytes, 0x200 bytes zero filled
Error Information (NVMe Log 0x01, 16 of 64 entries)
No Errors Logged
Warning: NVMe Get Log truncated to 0x200 bytes, 0x034 bytes zero filled
Self-test Log (NVMe Log 0x06, NSID 0xffffffff)
Self-test status: No self-test in progress
No Self-tests Logged
Back into the box
I disconnected that mobile carrier from the FreeBSD USB port. I installed it back onto the PCIe card, swapping it with another device. It was in the slot farthest from the fan. Now it’s one slow closer to the fan.
I booted up the host. And I see:
[15:29 r730-01 dvl ~] % zpool status data04
pool: data04
state: ONLINE
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Thu Jul 2 15:28:49 2026
1.73T / 9.30T scanned, 10.9G / 7.58T issued at 1.81G/s
1.84G resilvered, 0.14% done, 01:11:23 to go
config:
NAME STATE READ WRITE CKSUM
data04 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gpt/S7KGNU0Y722875X ONLINE 0 0 0
gpt/S7KGNU0Y915666E ONLINE 0 0 0
gpt/S7KGNU0Y912937J ONLINE 0 0 0
gpt/S7KGNU0Y912955D ONLINE 0 0 2 (resilvering)
gpt/S7U8NJ0Y716854P ONLINE 0 0 0
gpt/S7U8NJ0Y716801F ONLINE 0 0 0
gpt/S757NS0Y700758M ONLINE 0 0 0
gpt/S757NS0Y700760R ONLINE 0 0 0
errors: No known data errors
This is as good as can be expected. :)
About 10 minutes later:
[15:29 r730-01 dvl ~] % zpool status data04
pool: data04
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: resilvered 1.84G in 00:00:20 with 0 errors on Thu Jul 2 15:29:09 2026
config:
NAME STATE READ WRITE CKSUM
data04 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gpt/S7KGNU0Y722875X ONLINE 0 0 0
gpt/S7KGNU0Y915666E ONLINE 0 0 0
gpt/S7KGNU0Y912937J ONLINE 0 0 0
gpt/S7KGNU0Y912955D ONLINE 0 0 2
gpt/S7U8NJ0Y716854P ONLINE 0 0 0
gpt/S7U8NJ0Y716801F ONLINE 0 0 0
gpt/S757NS0Y700758M ONLINE 0 0 0
gpt/S757NS0Y700760R ONLINE 0 0 0
errors: No known data errors
All good. Let’s do a scrub before I clear out those errors.
[15:39 r730-01 dvl ~] % sudo zpool scrub data04
[15:40 r730-01 dvl ~] % zpool status data04
pool: data04
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub in progress since Thu Jul 2 15:40:05 2026
182G / 9.30T scanned at 45.6G/s, 0B / 9.30T issued
0B repaired, 0.00% done, no estimated completion time
config:
NAME STATE READ WRITE CKSUM
data04 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gpt/S7KGNU0Y722875X ONLINE 0 0 0
gpt/S7KGNU0Y915666E ONLINE 0 0 0
gpt/S7KGNU0Y912937J ONLINE 0 0 0
gpt/S7KGNU0Y912955D ONLINE 0 0 2
gpt/S7U8NJ0Y716854P ONLINE 0 0 0
gpt/S7U8NJ0Y716801F ONLINE 0 0 0
gpt/S757NS0Y700758M ONLINE 0 0 0
gpt/S757NS0Y700760R ONLINE 0 0 0
errors: No known data errors
Logs
Let’s find that device.
[15:41 r730-01 dvl ~] % grep S7KGNU0Y912955D /var/run/dmesg.boot
nda2: <Samsung SSD 990 PRO 4TB 4B2QJXD7 S7KGNU0Y912955D>
nda2: Serial Number S7KGNU0Y912955D
[12:31 r730-01 dvl ~] % zpool status
pool: data01
state: ONLINE
scan: scrub repaired 0B in 00:00:07 with 0 errors on Thu Jul 2 03:48:55 2026
config:
NAME STATE READ WRITE CKSUM
data01 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gpt/Y7P0A022TEVE ONLINE 0 0 0
gpt/Y7P0A02ATEVE ONLINE 0 0 0
gpt/Y7P0A02DTEVE ONLINE 0 0 0
gpt/Y7P0A02GTEVE ONLINE 0 0 0
gpt/Y7P0A02LTEVE ONLINE 0 0 0
gpt/Y7P0A02MTEVE ONLINE 0 0 0
gpt/Y7P0A02QTEVE ONLINE 0 0 0
gpt/Y7P0A033TEVE ONLINE 0 0 0
errors: No known data errors
pool: data02
state: ONLINE
scan: scrub repaired 0B in 00:03:59 with 0 errors on Thu Jul 2 03:52:59 2026
config:
NAME STATE READ WRITE CKSUM
data02 ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gpt/S6WSNJ0T208743F ONLINE 0 0 0
gpt/S6WSNJ0T207774T ONLINE 0 0 0
errors: No known data errors
pool: data03
state: ONLINE
scan: scrub repaired 0B in 01:16:19 with 0 errors on Thu Jul 2 05:05:31 2026
config:
NAME STATE READ WRITE CKSUM
data03 ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gpt/WD_22492H800867 ONLINE 0 0 0
gpt/WD_230151801284 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
gpt/WD_230151801478 ONLINE 0 0 0
gpt/WD_230151800473 ONLINE 0 0 0
errors: No known data errors
pool: data04
state: DEGRADED
status: One or more devices have been removed.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Online the device using zpool online' or replace the device with
'zpool replace'.
scan: scrub repaired 0B in 01:11:17 with 0 errors on Thu Jul 2 05:00:37 2026
config:
NAME STATE READ WRITE CKSUM
data04 DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
gpt/S7KGNU0Y722875X ONLINE 0 0 0
gpt/S7KGNU0Y915666E ONLINE 0 0 0
gpt/S7KGNU0Y912937J ONLINE 0 0 0
gpt/S7KGNU0Y912955D REMOVED 0 0 0
gpt/S7U8NJ0Y716854P ONLINE 0 0 0
gpt/S7U8NJ0Y716801F ONLINE 0 0 0
gpt/S757NS0Y700758M ONLINE 0 0 0
gpt/S757NS0Y700760R ONLINE 0 0 0
errors: No known data errors
pool: zroot
state: ONLINE
status: Some supported and requested features are not enabled on the pool.
The pool can still be used, but some features are unavailable.
action: Enable all features using 'zpool upgrade'. Once this is done,
the pool may no longer be accessible by software that does not support
the features. See zpool-features(7) for details.
scan: scrub repaired 0B in 00:00:53 with 0 errors on Thu Jul 2 03:50:16 2026
config:
NAME STATE READ WRITE CKSUM
zroot ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gpt/zfs0_20170718AA0000185556 ONLINE 0 0 0
gpt/zfs1_20170719AA1178164201 ONLINE 0 0 0
errors: No known data errors
Then I checked Nagios – it had found the same issue. I hadn’t check Nagios before today. Oh oh.
I went to LibreNMS to see if there was any trending information about that drive. It was not found. I suspect when it dropped out, LibreNMS also dropped it. If that’s the case, that’s not helpful.
Let’s try a reboot.
After a reboot, that drive (S7KGNU0Y912955D) was not found. My next idea: open up the case and reseat that device.
I’m hoping that device is not dead. It went into service 7 months ago and priced have jumped more than slightly lately.
When I checked another device:
[13:16 r730-01 dvl ~] % sudo smartctl -a /dev/nvme4
smartctl 7.5 2025-04-30 r5714 [FreeBSD 15.0-RELEASE-p11 amd64] (local build)
Copyright (C) 2002-25, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: Samsung SSD 990 EVO Plus 4TB
...
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 1%
Data Units Read: 76,836,586 [39.3 TB]
Data Units Written: 47,333,046 [24.2 TB]
Host Read Commands: 2,617,490,888
Host Write Commands: 1,200,934,619
Controller Busy Time: 8,225
Power Cycles: 23
Power On Hours: 6,562
...
That usage level is not outrageous. All units in this zpool should be more-or-less identically used.
Drive is not dead
I powered off the host, and pulled out the ASUS Hyper M.2 X16 Gen 4 card. I move the NVMe card in question to a portable carrier. I hooked that up to my Macbook. It was identified as a “Samsung SSD 990 PRO 4TB” – that tells me it’s not completely dead.
bsdimp suggested I hook that up to a FreeBSD box.
While monitoring /var/log/messages, I did just not. Nothing. :(
I tried another USB port; nothing. I then tried a USB port on the back of the host:
[15:03 r730-03 dvl ~] % sudo smartctl -a /dev/da8
smartctl 7.5 2025-04-30 r5714 [FreeBSD 15.0-RELEASE-p11 amd64] (local build)
Copyright (C) 2002-25, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: Samsung SSD 990 PRO 4TB
Serial Number: S7KGNU0Y912955D
Firmware Version: 4B2QJXD7
PCI Vendor/Subsystem ID: 0x144d
IEEE OUI Identifier: 0x002538
Total NVM Capacity: 4,000,787,030,016 [4.00 TB]
Unallocated NVM Capacity: 0
Controller ID: 1
NVMe Version: 2.0
Number of Namespaces: 1
Namespace 1 Size/Capacity: 4,000,787,030,016 [4.00 TB]
Namespace 1 Utilization: 3,057,326,026,752 [3.05 TB]
Namespace 1 Formatted LBA Size: 512
Namespace 1 IEEE EUI-64: 002538 4951a0eec6
Local Time is: Thu Jul 2 15:03:56 2026 UTC
Firmware Updates (0x16): 3 Slots, no Reset required
Optional Admin Commands (0x0017): Security Format Frmw_DL Self_Test
Optional NVM Commands (0x0055): Comp DS_Mngmt Sav/Sel_Feat Timestmp
Log Page Attributes (0x2f): S/H_per_NS Cmd_Eff_Lg Ext_Get_Lg Telmtry_Lg Log0_FISE_MI
Maximum Data Transfer Size: 512 Pages
Warning Comp. Temp. Threshold: 82 Celsius
Critical Comp. Temp. Threshold: 85 Celsius
Supported Power States
St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat
0 + 9.39W - - 0 0 0 0 0 0
1 + 9.39W - - 1 1 1 1 0 0
2 + 9.39W - - 2 2 2 2 0 0
3 - 0.0400W - - 3 3 3 3 4200 2700
4 - 0.0050W - - 4 4 4 4 500 21800
Supported LBA Sizes (NSID 0x1)
Id Fmt Data Metadt Rel_Perf
0 + 512 0 0
=== START OF SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART/Health Information (NVMe Log 0x02, NSID 0xffffffff)
Critical Warning: 0x00
Temperature: 34 Celsius
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 0%
Data Units Read: 56,743,286 [29.0 TB]
Data Units Written: 11,391,387 [5.83 TB]
Host Read Commands: 2,383,774,544
Host Write Commands: 425,045,375
Controller Busy Time: 802
Power Cycles: 21
Power On Hours: 5,614
Unsafe Shutdowns: 10
Media and Data Integrity Errors: 0
Error Information Log Entries: 0
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Temperature Sensor 1: 34 Celsius
Temperature Sensor 2: 36 Celsius
Warning: NVMe Get Log truncated to 0x200 bytes, 0x200 bytes zero filled
Error Information (NVMe Log 0x01, 16 of 64 entries)
No Errors Logged
Warning: NVMe Get Log truncated to 0x200 bytes, 0x034 bytes zero filled
Self-test Log (NVMe Log 0x06, NSID 0xffffffff)
Self-test status: No self-test in progress
No Self-tests Logged
Back into the box
I disconnected that mobile carrier from the FreeBSD USB port. I installed it back onto the PCIe card, swapping it with another device. It was in the slot farthest from the fan. Now it’s one slow closer to the fan.
I booted up the host. And I see:
[15:29 r730-01 dvl ~] % zpool status data04
pool: data04
state: ONLINE
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Thu Jul 2 15:28:49 2026
1.73T / 9.30T scanned, 10.9G / 7.58T issued at 1.81G/s
1.84G resilvered, 0.14% done, 01:11:23 to go
config:
NAME STATE READ WRITE CKSUM
data04 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gpt/S7KGNU0Y722875X ONLINE 0 0 0
gpt/S7KGNU0Y915666E ONLINE 0 0 0
gpt/S7KGNU0Y912937J ONLINE 0 0 0
gpt/S7KGNU0Y912955D ONLINE 0 0 2 (resilvering)
gpt/S7U8NJ0Y716854P ONLINE 0 0 0
gpt/S7U8NJ0Y716801F ONLINE 0 0 0
gpt/S757NS0Y700758M ONLINE 0 0 0
gpt/S757NS0Y700760R ONLINE 0 0 0
errors: No known data errors
This is as good as can be expected. :)
About 10 minutes later:
[15:29 r730-01 dvl ~] % zpool status data04
pool: data04
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: resilvered 1.84G in 00:00:20 with 0 errors on Thu Jul 2 15:29:09 2026
config:
NAME STATE READ WRITE CKSUM
data04 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gpt/S7KGNU0Y722875X ONLINE 0 0 0
gpt/S7KGNU0Y915666E ONLINE 0 0 0
gpt/S7KGNU0Y912937J ONLINE 0 0 0
gpt/S7KGNU0Y912955D ONLINE 0 0 2
gpt/S7U8NJ0Y716854P ONLINE 0 0 0
gpt/S7U8NJ0Y716801F ONLINE 0 0 0
gpt/S757NS0Y700758M ONLINE 0 0 0
gpt/S757NS0Y700760R ONLINE 0 0 0
errors: No known data errors
All good. Let’s do a scrub before I clear out those errors.
[15:39 r730-01 dvl ~] % sudo zpool scrub data04
[15:40 r730-01 dvl ~] % zpool status data04
pool: data04
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub in progress since Thu Jul 2 15:40:05 2026
182G / 9.30T scanned at 45.6G/s, 0B / 9.30T issued
0B repaired, 0.00% done, no estimated completion time
config:
NAME STATE READ WRITE CKSUM
data04 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gpt/S7KGNU0Y722875X ONLINE 0 0 0
gpt/S7KGNU0Y915666E ONLINE 0 0 0
gpt/S7KGNU0Y912937J ONLINE 0 0 0
gpt/S7KGNU0Y912955D ONLINE 0 0 2
gpt/S7U8NJ0Y716854P ONLINE 0 0 0
gpt/S7U8NJ0Y716801F ONLINE 0 0 0
gpt/S757NS0Y700758M ONLINE 0 0 0
gpt/S757NS0Y700760R ONLINE 0 0 0
errors: No known data errors
Logs
Let’s find that device.
[15:41 r730-01 dvl ~] % grep S7KGNU0Y912955D /var/run/dmesg.boot
nda2: <Samsung SSD 990 PRO 4TB 4B2QJXD7 S7KGNU0Y912955D>
nda2: Serial Number S7KGNU0Y912955D
It is now nda2 – given it was nvme3 before, and it moved slots, I figure that’s our device.
[15:43 r730-01 dvl ~] % sudo nvmecontrol logpage -p 2 nvme2
SMART/Health Information Log
============================
Critical Warning State: 0x00
Available spare: 0
Temperature: 0
Device reliability: 0
Read only: 0
Volatile memory backup: 0
Temperature: 313 K, 39.85 C, 103.73 F
Available spare: 100
Available spare threshold: 10
Percentage used: 0
Data units (512,000 byte) read: 56780042
Data units written: 11396179
Host read commands: 2385648136
Host write commands: 425345148
Controller busy time (minutes): 802
Power cycles: 22
Power on hours: 5614
Unsafe shutdowns: 10
Media errors: 0
No. error info log entries: 0
Warning Temp Composite Time: 0
Error Temp Composite Time: 0
Temperature Sensor 1: 313 K, 39.85 C, 103.73 F
Temperature Sensor 2: 326 K, 52.85 C, 127.13 F
Temperature 1 Transition Count: 0
Temperature 2 Transition Count: 0
Total Time For Temperature 1: 0
Total Time For Temperature 2: 0
An hour or so later
Phew.
[16:50 r730-01 dvl ~/bin] % zpool status data04
pool: data04
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub repaired 0B in 01:10:47 with 0 errors on Thu Jul 2 16:50:52 2026
config:
NAME STATE READ WRITE CKSUM
data04 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gpt/S7KGNU0Y722875X ONLINE 0 0 0
gpt/S7KGNU0Y915666E ONLINE 0 0 0
gpt/S7KGNU0Y912937J ONLINE 0 0 0
gpt/S7KGNU0Y912955D ONLINE 0 0 2
gpt/S7U8NJ0Y716854P ONLINE 0 0 0
gpt/S7U8NJ0Y716801F ONLINE 0 0 0
gpt/S757NS0Y700758M ONLINE 0 0 0
gpt/S757NS0Y700760R ONLINE 0 0 0
errors: No known data errors
[16:51 r730-01 dvl ~/bin] % sudo zpool clear data04
[16:51 r730-01 dvl ~/bin] % zpool status data04
pool: data04
state: ONLINE
scan: scrub repaired 0B in 01:10:47 with 0 errors on Thu Jul 2 16:50:52 2026
config:
NAME STATE READ WRITE CKSUM
data04 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gpt/S7KGNU0Y722875X ONLINE 0 0 0
gpt/S7KGNU0Y915666E ONLINE 0 0 0
gpt/S7KGNU0Y912937J ONLINE 0 0 0
gpt/S7KGNU0Y912955D ONLINE 0 0 0
gpt/S7U8NJ0Y716854P ONLINE 0 0 0
gpt/S7U8NJ0Y716801F ONLINE 0 0 0
gpt/S757NS0Y700758M ONLINE 0 0 0
gpt/S757NS0Y700760R ONLINE 0 0 0
errors: No known data errors
[16:51 r730-01 dvl ~/bin] %
Seems OK now.
The next day
The next day, Friday Jul 3 2026, all was still well. I went looking for temperatures spikes.
I found on, only for the basement room temperature. It had hit 80F for the first time since last summer. See graphs below.
It could be that was enough to loosen the connection between that M.2 device and its connector. This device, and others, were installed in December of 2025 (about 5 months ago) when the temperature was about 55F. NOTE: This stick was the farthest from the fan. If the next device to drop is S7KGNU0Y912937J, we’ll know the position is relevant.
Usualcaveatemptor here:whatI‘mwritinghereismypersonalopinion,andwhileitdoesrelatetoafieldmycurrentemployer(Meta)hasinterestin,itdoesnotrepresentthe views of my current, past, or future employers. Yes we all get bored by these preambles, but if you want to still be able to hear the opinions of seasoned engineers you’ll have to live with them. I personally would not want to lose my job because my posts are reported as being related to it. They’re not.
Over the past year, if you are a tech enthusiast, you cannot have missed the raise of a new class of software, which I personally started referring to as APA, ArtificialPersonalAssistant. Both because I dislike the “claws” name, and because as it was predicable a number of projects are now spawning to refine (pun intended) the concept and in some case “productify” it. I have played around with a couple of these projects (harnesses? frameworks?) if nothing else because in my profession I don’t get to choose not to engage at all with the newest hype without a good reason. I even engaged, at one time, with Bitcoin, if nothing else to know exactly why I did not want to ever touch any other carboncurrencies in my life.
I could be writing about what I expect these APAs to achieve, both in terms of wins and losses for society, of course. But that’s not honestly something I have enough expertise to write about. I’m sure that there are plenty of opinionists that will provide their hot takes as time goes by, and about as many actual researchers looking to make a study of them that will not get as many readers as the scary headlines. (Yes I’m being a bit cynical here.) Instead, I want to focus on one problem that has been nibbling at the back of my mind for many years now: who is the identity behind an account?
You may remember that a few years back I have written about my difficulties with setting up password sharing with my then-girlfriend (and now wife), as well as with my mother and my sister for different sets of accounts. The solution I’m using to this day is not really my favourite: for most (but not all, for various reasons) accounts, we now use shared email aliases, some of which go to me and my wife, others to me, my mother and sister, and some others going to my wife and her mother. This allows us to at least receive all the required notifications to handle these “shared” accounts, but they are, still, in an individual name. These become annoying when you have to call and they request to talk to the account holder.
I have to say I’m particularly surprised that, after this many years of digital life, we still haven’t solved the problem that many accounts belong to a family, more than to an individual. I know quite a few services allow supervised accounts for minors (my employer does that for Instagram, to the best of my understanding — I don’t work on that product and I have no need for supervised accounts so I have no idea how any of that works), and I believe Apple is the state of the art in terms of “family accounts”, but I have not used an Apple product outside of work for over ten years. Google theoretically supports “Google One Family” accounts, but the only features that appear to be useful at that point are Google Play paid-app sharing (which is also almost impossible to confirm before buying the app!) At the very least I would enjoy having a “Family Drive” where the files are organized together, instead of being shared “individually”, but I fear that particular feature is still gated behind the professional Workspace product (which explicitly shed any notion of being usable for families years back.)
Banks and other financial institutions, of course, already mostly know how to deal with this. Joint current accounts have been a thing for decades, and most credit card issuers have a concept of “additional cardholders” with more or less access to the card’s information. For example, American Express allows my wife to see all of her transactions in real time, as well as the offers and membership points, while my “main cardholder” account includes both our transactions, statements and so on. But somehow most of the household bills end up in a single account holder: power, broadband, mobile phones… Octopus is at least a little better in terms of being able to put both names on the account and thus count us both as account holders, but even that required us to send an email as it is not part of the normal flow of operations online.
But how does this even connect to APAs? Well, from a certain point of view, APAs could be considered similar to supervised minors. And my personal preference when playing with them, is for them to get theirown accounts and identities, even though the default path that most people seem to take is to provide them with full access to their own (the user’s) accounts. This is understandable, as often registering a second account for the same service is considered a violation of the Terms of Service. Or it’s just incredibly complicated and fraught with issues. For instance, I tried providing my most recent APA with its own GitHub account – both so that it is very clear for the receiving end that they are interacting with an APA, and to make it clear on who the person responsible for the APA’s behaviour is (me) – but at first the account has been restricted and left pending review for nearly a month. I don’t blame GitHub: ensuring fairness for contributors on both the executing and receiving side requires a complex balance of intention and letter of the terms. Eventually, the account was reinstated, and even made its first contributions.
As an aside, I’m very much throwing anything that the APA is generating to the public as 0BSD, the most accepted intentionally permissive license I’m aware of.
Part of the problem is that the type of accounts that APAs would end up using are not new for most of these services, they just are not the kind of accounts those services have wanted to have in the first place: bot accounts. For the longest time, bot accounts have been the adversary, bringing nothing but spam and negative value content, at least outside of the enterprise space, which is why often the APIs for supervised bot accounts actually exist, but they’re behind a paywall, or at least restricted to use in ringfenced aspects, such as GitHub organizations. It also meant that the “valid” bot accounts would be balanced against the number of users they supported. A company with a dozen employees and a couple of bots is easier to support than a reality where every geek out there ends up with their own personal bot, or even more than one.
But to be clear, the problems and limitations around supervised bot identities do not stop at commercial services. Even when taking my least favourite option, the self-hosted path, there rarely are proper paths for these bots to be supervised: Nextcloud doesn’t have this as an option (though at least in some features it supports delegates), Home Assistant has an extremely coarse-grained permission system (at least for now, who knows, they can change it next month for all I know!), and good luck trying to get a read-only password set up with Mail-U.
And some of these end up being a horrible game of ping-pong between them. I would like for my household-wide APA to have access to both my and my wife’s calendars, and the shared “Family” calendar. We share each other calendars’ already, but we have our own mostly so that we don’t get reminded to go to an appointment than the other is due for…
… but it turned out to be a lot more complex than that. Google Calendar APIs require OAuth2 permissions to access the calendar in read-write mode. You can get a testing API key for that, but it needs reauthentication every seven days which is completely pointless for an APA. And for companies (Office APA? More like an Artificial Receptionist then) you have the option to make the key internal — but if you need to share it with two consumer accounts? You need to go through the whole verification as if the app was a launched startup! Ridiculous!
So I looked into alternative solutions and tried Radicale… and it’s almost as terrible. Well, it’s not as much terrible as it is not designed for either humans or bots. It’s over complicated to set up, with custom configuration languages and direct filesystem access, but also still relies on you providing authentication separately (okay that’s “easy” with Authelia thankfully) and even then you get no UI so you need to find something you can use with it, because sure as heck you can’t use Google Calendar on Android for that.
I have, eventually, found a half-decent way to test this out with aCalendar+ and DAVx⁵, but besides both apps costing money (sure, you can get DAVx⁵ on F-Droid, or build it yourself, but that’s not feasible for most people), they’re just… clunky. The fact that you need two separate apps to be able to get there is already annoying, but even then… oh and let’s not forget that Nextcloud doesn’t do calendar from their own Android app! Maybe everyone is using Macs and iPhones so they don’t care about the rest of us normies?
And this is without going back to “What is an email?” and the fact that oh-so-many authentication services require a strict correlation between email addresses and accounts — which doesn’t really work when you decide to use shared email aliases, and in particular, per-service shared email aliases.
For instance, any Shopify shop ends up recognizing you by email address, to the point that if you pay with PayPal, it will just use that email address for your order. Which is fine for an individual, but quite a lot more annoying when my wife wants to know when the thing I ordered arrives, while I’m on the other side of the world for a work trip. And it became annoying to me because, up until recently, my Shop app recognized email wasn’t the same as PayPal — mostly as a result of my having had PayPal now in four separate countries (and not having been able to immediately delete the old accounts when creating a new one.)
None of these are particularly novel problems, none of these are Earth-shattering, but they’re definitely going to be the kind of problem a lot of engineers will have to solve, or at least attempt to solve, if they want their software to fit in with a world that, whether we like it or not, is going to adopt some level of LLM automation, in form of Artificial Personal Assistants and the like.
Because the alternative, which is scary to me but unfortunately extremely likely, is that users of these artificial assistants will simply give them the passwords of their main accounts. Which is both risky for the users’ data (would you really let an LLM delete your emails without you?), and a bad experience for whoever is on the other side of a conversation (are you talking to a person, or to a bot?)
Or maybe Douglas Adams was right once again, and we’re on our way to have electric monks. On horses, of course.
🚀 MMO 20044: Season 4 startet – Neue Features & Balance-Änderungen
Die vierte Runde unseres strategischen Browser-MMO geht an den Start! Season 4 bringt spannende Neuerungen, verbessertes Balancing und mehr Interaktion zwischen den Spielern.
---
📢 Was ist neu in Season 4?
⚔️ Genesis-Angriffe: Strategische Sabotage
Ab sofort können Spieler mit aktivem Genesis-Projekt direkt angegriffen werden! Ein erfolgreicher Genesis-Angriff:
Verzögert das Genesis-Projekt des Verteidigers um 18 Stunden
Kostet den Angreifer 300 Ticks
Setzt einen 24-Stunden-Cooldown für den Angreifer
Garantiert den Sieg für den Angreifer (kein Zufall)
⚠️ Wichtig: Die maximale Bauzeit ist auf 24 Stunden gedeckelt – kein Spieler kann durch multiple Angriffe dauerhaft blockiert werden!
🛒 Gadget-Händler: Spezialfähigkeiten kaufen
Besuche den Gadget-Händler (alle 8 Stunden verfügbar) und kaufe nützliche Einmal-Effekte:
The Travel Grant Application for EuroBSDCon 2026 is now open. The Foundation can help you attend EuroBSDCon through our travel grant program. Travel grants are available to FreeBSD developers and advocates who need assistance with travel expenses for attending conferences related to FreeBSD development. Applications are due July 7, 2026. Find out more and apply today.
Did you know the Foundation also provides grants for other technical events? If you feel that your attendance at one of these events will benefit the FreeBSD Project and Community, and you need assistance getting there, please fill out the general travel grant application. Your application must be received 7 weeks prior to the event.
If, after moving to pkgbase (for me, that was via pkgbasify), you discover you can’t find the package in question, you might, like me, run this command:
At BSDCan 2026, I attended the pkgbase in Production: A Practical Overview talk. What impressed me was the ease with which one could upgrade from 15.0 to 15.1 etc. Included in the demonstration was pkgbasify (“Automatically convert a FreeBSD system to use pkgbase”).
I created my own new boot environment (BE). This is where I could fall back, should the upgrade fail. The upgrade process will ask if you want to create a new BE. See blow.
This is not in the instructions, but I did it anyway.
[17:41 r730-01 dvl ~] % sudo freebsd-update fetch install
src component not installed, skipped
Looking up update.FreeBSD.org mirrors... 3 mirrors found.
Fetching public key from update2.freebsd.org... done.
Fetching metadata signature for 15.0-RELEASE from update2.freebsd.org... done.
Fetching metadata index... done.
Fetching 2 metadata files... done.
Inspecting system... done.
Preparing to download files... done.
No updates needed to update system to 15.0-RELEASE-p10.
No updates are available to install.
All this was done as root. I did not want to invoke sudo for this.
root@r730-01:~ # tmux
root@r730-01:~ # ./pkgbasify.lua
Running this tool will irreversibly modify your system to use pkgbase.
This tool and pkgbase are experimental and may result in a broken system.
It is highly recommended to backup your system before proceeding.
Do you accept this risk and wish to continue? (y/n) y
Found unexpected symlinks in /etc
/etc/aliases.db
These symlinks will be overwritten by pkg(8) if they conflict with files in
base system packages. Please ensure that your system configuration will not be
broken if these symlinks are overwritten.
Continue and overwrite symlinks in /etc? (y/n) y
Updating FreeBSD-base repository catalogue...
FreeBSD-base repository is up to date.
Updating local repository catalogue...
Fetching meta.conf: 100% 179 B 0.2 kB/s 00:01
Fetching data: 100% 357 KiB 365.8 kB/s 00:01
Processing entries: 100%
local repository update completed. 967 packages processed.
All repositories are up to date.
Checking integrity... done (0 conflicting)
Your packages are up to date.
Updating FreeBSD-ports repository catalogue...
Fetching meta.conf: 100% 179 B 0.2 kB/s 00:01
Fetching data: 100% 10 MiB 11.0 MB/s 00:01
Processing entries: 100%
FreeBSD-ports repository update completed. 37066 packages processed.
Updating FreeBSD-ports-kmods repository catalogue...
Fetching meta.conf: 100% 179 B 0.2 kB/s 00:01
Fetching data: 100% 35 KiB 35.9 kB/s 00:01
Processing entries: 100%
FreeBSD-ports-kmods repository update completed. 240 packages processed.
Updating FreeBSD-base repository catalogue...
Fetching meta.conf: 100% 179 B 0.2 kB/s 00:01
Fetching data: 100% 80 KiB 82.3 kB/s 00:01
Processing entries: 100%
FreeBSD-base repository update completed. 496 packages processed.
All repositories are up to date.
Create a boot environment before conversion? (y/n) y
Another BE is created. I’m OK with that. Now we have:
[17:52 r730-01 dvl ~] % bectl list
BE Active Mountpoint Space Created
before-pkgbasify - - 3.85M 2026-06-29 17:39
default NR / 16.3G 2025-11-25 17:17
pre-pkgbasify_2026-06-29_175241 - - 344K 2026-06-29 17:52
I looked through /etc/master.passwd, looked right to me. I ssh’d from a new terminal session. Worked. I tried su, worked. Seems good there.
/etc/group looked right too. I didn’t check /etc/ssh/sshd_config, but ssh worked. Even after restarting sshd.
Well. Here goes:
[17:58 r730-01 dvl ~] % sudo shutdown -r now
Shutdown NOW!
shutdown: [pid 72325]
[17:58 r730-01 dvl ~] %
*** FINAL System shutdown message from dvl@r730-01.int.unixathome.org ***
System going down IMMEDIATELY
Connection to r730-01.int.unixathome.org closed by remote host.
Connection to r730-01.int.unixathome.org closed.
After reboot
This seems fine.
[14:00 pro05 dvl ~] % r730
Last login: Mon Jun 29 17:58:06 2026 from pro05.startpoint.vpn.unixathome.org
[18:03 r730-01 dvl ~] % uptime
6:03PM up 1 min, 1 user, load averages: 3.17, 0.83, 0.31
There I was, minding my own business, when this jumped up and hit me.
[root@tallboy:~] # sudo bectl create before-pkgbasify
[root@tallboy:~] # uname -a
FreeBSD tallboy.unixathome.org 15.0-RELEASE-p10 FreeBSD 15.0-RELEASE-p10 GENERIC amd64
[root@tallboy:~] # fetch https://github.com/FreeBSDFoundation/pkgbasify/raw/refs/heads/main/pkgbasify.lua
pkgbasify.lua 21 kB 1910 kBps 00s
[root@tallboy:~] # chmod +x ./pkgbasify.lua
[root@tallboy:~] # ./pkgbasify.lua
/var/empty is a readonly zfs filesystem.
This will cause conversion to fail as pkg will be unable to set the time of
/var/empty. Set readonly=off and run pkgbasify again.
[root@tallboy:~] #
So, what do we have here?
[root@tallboy:~] # zfs list | grep /var/empty
system/var/empty 96K 262G 96K /var/empty
[root@tallboy:~] # zfs get readonly system/var/empty
NAME PROPERTY VALUE SOURCE
system/var/empty readonly on local
[root@tallboy:~] #
This is an 11 year old system:
[root@tallboy:~] # zfs get creation system
NAME PROPERTY VALUE SOURCE
system creation Tue Feb 17 23:44 2015 -
It is not the only such host I have with this filesystem. See:
[14:21 zuul dvl ~] % zfs list | grep empty
system/var/empty 144K 150G 144K /var/empty
[14:21 zuul dvl ~] % zfs get readonly system/var/empty
NAME PROPERTY VALUE SOURCE
system/var/empty readonly on local
[14:22 zuul dvl ~] % zfs get creation system
NAME PROPERTY VALUE SOURCE
system creation Sat Dec 7 0:28 2013 -
Even older, but that host (zuul) has not been updated yet.
Either this is lingering issue from how zroot used to be set out, or it’s something I did myself, way-back-when.
syslog-ng-4.11.0_2 (sending logs from FreshPorts production)
victoria-logs-1.50.0_2 (receiving logs in the logs jail
The period in question
Looking at /var/log/messages, I see:
Jun 29 17:58:06 r730-01 shutdown[72325]: reboot by dvl:
Jun 29 17:58:06 r730-01 root[72379]: shutting down jail stage-nginx01
Jun 29 17:58:07 r730-01 root[72634]: jail stage-nginx01 has shut down
Jun 29 17:58:08 r730-01 root[72679]: shutting down jail test-nginx01
Jun 29 17:58:08 r730-01 kernel: test-nginx01
...
Jun 29 17:59:08 r730-01 root[83022]: jail dns1 has shut down
Jun 29 17:59:09 r730-01 nrpe[2797]: Caught SIGTERM - shutting down...
Jun 29 17:59:09 r730-01 nrpe[2797]: Daemon shutdown
Jun 29 17:59:09 r730-01 kernel: .
Jun 29 17:59:09 r730-01 bacula-fd[2557]: Shutting down Bacula service: r730-01-fd ...
Jun 29 17:59:09 r730-01 ntpd[2546]: ntpd exiting on signal 15 (Terminated)
Jun 29 17:59:09 r730-01 ntpd[2546]: ntpd exiting on signal 15 (Terminated)
Jun 29 18:00:06 r730-01 syslogd: exiting on signal 15
With syslogd now stopped, there are no further logs until:
Jun 29 18:02:51 r730-01 syslogd: kernel boot file is /boot/kernel/kernel
Jun 29 18:02:51 r730-01 kernel: Jun 29 18:00:06 r730-01 syslogd: exiting on signal 15
Jun 29 18:02:51 r730-01 kernel: pflog0: promiscuous mode disabled
Jun 29 18:02:51 r730-01 kernel: tap0: link state changed to DOWN
Jun 29 18:02:51 r730-01 kernel: Waiting (max 60 seconds) for system process `vnlru' to stop... done
...
Jun 29 18:03:49 r730-01 kernel: stage-nginx01.
Jun 29 18:05:11 r730-01 dvl[81436]: trying to start jail logs...
Jun 29 18:05:11 r730-01 dvl[81891]: jail logs has started
NOTE: I had not set the logs jail to start automatically. The above was me starting the jail from the command line.
What I’m looking for
I want to know if there are any logs between 18:00:06 and
18:05:11
in VictoriaLogs.
If there are, it means VictoriaLogs caught up after being offline. More precisely, the log submitters kept track of what had and had not been sent during the downtime.
Here we go:
Victoria logs for 18:00:00 to 18:06:00 showing 4,223 entries – the graph at the top of the page has no gaps.
So now I know. At present, I’m using only syslog-ng to forward logs into VictoriaLogs. If I start using another tool, I’ll want to confirm it also has buffering.
The Valuable News weekly series is dedicated to provide summary about news, articles and other interesting stuff mostly but not always related to the UNIX/BSD/Linux systems. Whenever I stumble upon something worth mentioning on the Internet I just put it here.
Today the amount information that we get using various information streams is at massive overload. Thus one needs to focus only on what is important without the need to grep(1) the Internet everyday. Hence the idea of providing such information ‘bulk’ as I already do that grep(1).
The Usual Suspects section at the end is permanent and have links to other sites with interesting UNIX/BSD/Linux news.
Past releases are available at the dedicated NEWS page.
Die dritte Runde unseres browserbasierten MMO-Strategiespiels geht zu Ende, und wir haben einen klaren Sieger: onli hat als Erster Level 5 der Genesis erreicht und damit Season 3 für sich entschieden! 🎉
Rückblick: Season 3
Season 3 war geprägt von einer deutlich größeren Galaxie mit 100 Sternensystemen (doppelt so groß wie zuvor) und wichtigen Spielverbesserungen:
Aktions-Warteschlange: Endlich kein Warten mehr! Bis zu vier Reisen und vier Forschungsaufträge lassen sich vorausplanen. Flotte und Labor arbeiten unabhängig – simultaneously reisen und forschen war erstmals möglich.
Verbesserte Galaxiekarte: Laufende Reisen werden als Linien angezeigt, Piratenschätze sind markiert, und eine Legende erklärt alle Symbole.
Erweiterter Chat: Längere, mehrzeilige Nachrichten für bessere Koordination.
Kleine, aber feine Anpassungen: Konkrete Reisezeiten an Warptoren, höherer Ertrag beim Abbau der Heimatwelt, zuverlässige Produktionszyklen.
Trotz der größeren Galaxie hat onli als Kael-Spieler die Konkurrenz hinter sich gelassen und den Countdown ausgelöst. Herzlichen Glückwunsch! 🏆
Die Trophäe für Season 3 geht damit an onli! und ja, wir haben nicht vergessen, sie zu vergeben!
Vorschau: Was Season 4 bringt
Während Season 3 noch ohne direkte Interaktion zwischen den Genesis-Projekten auskam, wird Season 4 mit einem spannenden neuen Feature aufwarten: Genesis-Angriffe!
⚡ Genesis-Angriffe: Strategische Sabotage
Ab Season 4 können Spieler mit aktivem Genesis-Projekt direkt angegriffen werden! erfolgreicher Genesis-Angriff kostet den Angreifer 300 Ticks und:
Verzögert das Genesis-Projekt des Verteidigers um 18 Stunden
Setzt einen 24-Stunden-Cooldown für den Angreifer (pro Ziel)
Garantiert den Sieg für den Angreifer (kein Zufall – reine Tick-Kosten)
Erscheint in der Kampfhistorie mit eigenem Battle-Report
Wichtig: Um die Balance zu wahren und sicherzustellen, dass alle Spieler fair Ära-Galaxie 5 erreichen können, gibt es eine maximale Bauzeit von 24 Stunden. Das bedeutet:
Genesis-Angriffe setzen die Bauzeit auf mindestens 18 Stunden
Mehrere Angriffe hintereinander können die Bauzeit nicht ins Unendliche treiben
Sabotage-Sonden (neues Gadget, siehe unten) verlängern um 3 Stunden – aber nie über 24 Stunden hinaus
Jeder kann ÄG5 erreichen – strategische Angriffe verzögern den Fortschritt, blockieren ihn aber nicht dauerhaft
Diese Deckelung verhindert, dass die Bauzeit durch koordinierte Angriffe multiple Spieler „ausgesperrt“ werden können. Fairplay steht im Vordergrund!
🎁 Gadget-Händler: Spezialeffekte für Ressourcen
Season 4 führt ein neues Wirtschaftssystem ein: den Gadget-Händler. besuchen des Händlers (über das Dashboard) bietet spezielle Gadgets zum Kauf an – nützliche Einmal-Effekte, die Ressourcen verbrauchen:
Notschild: 50 Kristalle → +50% Verteidigungsbonus für den nächsten eingehenden Angriff
Boost-Triebwerk: 200 Rohstoffe → Nächste Reise kostet nur die Hälfte an Ticks
Saboteur-Sonde: 5 Artefakte → Verzögert fremdes Genesis-Projekt um 3 Stunden
Jeder Gadget-Typ kann nur begrenzt gelagert werden (z. B. max. 2 Saboteur-Sonden), was den strategischen Einsatz fördert.
🌌 Weitere Verbesserungen
Nebst den großen Features gibt es weitere Optimierungen:
Rassen-Boni: Jede Rasse hat nun einzigartige Stärken – Ashar mit Angriffsbonus, Kael mit Produktionsvorteilen, Cyborg mit Ausdauer, Mensch als Allrounder
Genesis-Seite: Übersichtlicher Fortschritt, Upkeep-Kosten und Bauzeit-Informationen auf einen Blick
Kampfberichte: Genesis-Angriffe erhalten eigene Berichte mit klarer Kennzeichnung
Dashboard: Genesis-Angriffs-Checkbox direkt im Angriffsformular
Fazit & Ausblick
Season 3 war ein voller Erfolg mit onli als verdientem Sieger. Season 4 wird mit Genesis-Angriffen und dem Gadget-System noch mehr strategische Tiefe und Interaktion zwischen den Spielern bringen – ohne dabei den Fortschritt anderer dauerhaft zu blockieren.
Die wichtigste Botschaft: Ära-Galaxie 5 bleibt für alle erreichbar! Die 24-Stunden-Deckelung der Bauzeit stellt sicher, dass auch bei intensiver Sabotage niemand permanent aus dem Rennen geworfen wird.
Wir freuen uns auf eine spannende Season 4 – möge die beste Strategie gewinnen! 🚀
libexpat is a fast streaming XML parser.
Alongside libxml2, Expat is one of the
most widely used
software libre XML parsers written in C, specifically C99.
It is cross-platform and licensed under
the MIT license.
Expat 2.8.2
was released
today.
The key motivation for cutting a release and doing so now
was getting security and non-security bugfixes out to users.
On the security side, 13 vulnerabilities have been fixed:
Two men pleaded guilty in the United Kingdom this week to criminal charges stemming from an August 2024 cyberattack that crippled Transport for London, the entity responsible for the public transport network in the Greater London area. The duo were key members of a prolific cybercrime group known as Scattered Spider, and their guilty pleas came on the first day of what was expected to be a six-week trial.
Owen Flowers (left) 18, and Thalha Jubair, 20. Image: UK National Crime Agency (NCA).
Thalha Jubair, 20, of East London and 18-year-old Owen Flowers of Walsall admitted conspiring to commit unauthorized acts against Transport for London computer systems and causing risk of serious damage to human welfare. According to a report from the BBC, Flowers alone admitted to being part of a conspiracy to hack into U.S. based healthcare providers SSM Health Care Corporation and Sutter Health in September 2024.
Jubair is also wanted by U.S. law enforcement agencies. In September 2025, prosecutors in New Jersey unsealed an indictment alleging Jubair and other Scattered Spider members committed computer fraud, wire fraud, and money laundering in relation to 120 computer network intrusions involving 47 U.S. entities between May 2022 and September 2025, and that the group’s victims paid at least $115 million in ransom payments.
In July 2025, KrebsOnSecurity reported that Flowers and Jubair were arrested in the United Kingdom in connection with Scattered Spider ransom attacks against the retailers Marks & Spencer and Harrods, and the British food retailer Co-op Group. Multiple sources familiar with those investigations said Flowers was the Scattered Spider member who anonymously gave interviews to the media in the days after the group’s September 2023 ransomware attacks disrupted operations at Las Vegas casinos operated by MGM Resorts and Caesars Entertainment.
According to prosecutors, Jubair co-ran a bustling Telegram channel called Star Chat, the home of a SIM-swapping group that used voice- and SMS-based phishing attacks to steal credentials from employees at the major wireless providers in the U.S. and U.K. The group would then use that access to sell a service that could redirect a target’s phone number to a device the attackers controlled and intercept the victim’s calls and text messages (including one-time codes for multi-factor authentication).
A receipt from Star Fraud Chat’s SIM-swapping service targeting a T-Mobile customer after the group gained access to internal T-Mobile employee tools. “Rocket Ace” was one of Jubair’s hacker handles, according to U.S. prosecutors.
New Jersey prosecutors also allege Jubair also was involved in a mass SMS phishing campaign during the summer of 2022 that stole single sign-on credentials from employees at hundreds of companies. That weeks-long SMS phishing campaign led to intrusions and data thefts at more than 130 organizations, including LastPass, DoorDash, Mailchimp, Plex and Signal.
KrebsOnSecurity reported last year that one of Jubair’s alter egos at age 15 was “Everlynn,” a hacker who sold fraudulent “emergency data requests” that used compromised police and government email addresses to demand subscriber data (e.g. username, IP/email address) from major tech companies, claiming the requests concerned urgent matters of life and death and could not wait for a court order.
In April 2026, 24-year-old British national and Scattered Spider member Tyler “Tylerb” Buchananpleaded guilty to wire fraud conspiracy and aggravated identity theft for participating in the group’s SMS phishing spree in the summer of 2022. The government said Buchanan, Jubair and others used the credentials harvested in that phishing campaign to steal at least $8 million in cryptocurrency from victims throughout the United States. Buchanan is currently scheduled to be sentenced on October 2.
In August 2025, 20-year-old Scattered Spider member from Florida named Noah Michael Urban was sentenced to 10 years in federal prison and ordered to pay $13 million in restitution, after pleading guilty to charges of wire fraud and conspiracy.
The U.S. Department of Justice says three alleged Scattered Spider defendants indicted along with Buchanan still face charges, including Ahmed Hossam Eldin Elbadawy, 24, a.k.a. “AD,” of College Station, Texas; Evans Onyeaka Osiebo, 21, of Dallas, Texas; and Joel Martin Evans, 26, a.k.a. “joeleoli,” of Jacksonville, North Carolina.
Flowers and Jubair are slated to be sentenced in a London court on July 15, 2026.
Wir haben im März 2025 die Gasheizung abgeschaltet.
Seitdem - also seit mehr als einem Jahr - heizen und kühlen wir das Haus mit Klimageräten, also Luft-Luft-Wärmepumpen.
Die erste Beschreibung der Installation steht in Going fully electric
,
die Auswertung nach einem Jahr in One year gas-free
.
Das kurze Ergebnis: Es funktioniert.
Im Winter wird das Haus schnell warm.
Im Sommer bleibt der Arbeitsplatz unter dem Dach bei 23,5 Grad stabil, auch wenn es draußen heiß ist.
Temperatur am Arbeitsplatz unter dem Dach: Morgens fällt die Temperatur nach dem Einschalten des Klimagerätes von 26 Grad auf 23,5 Grad und bleibt dort stabil.
Das Projekt ist nicht nur “Gasheizung raus, Klimageräte rein”.
Es ist Teil einer fast fünf Jahre langen Umstellung:
Test mit einem Carver S+ als kleinem Elektrofahrzeug für lokale Fahrten.
Installation einer Ost-West-Solaranlage mit 3,3 kWp auf der Ostseite und 6,6 kWp auf der Westseite, zusammen 9.250 Wp.
Installation eines 11-kW-Ladeanschlusses und Kauf eines gebrauchten Megane e-Tech 60 kWh (Jahreswagen).
Abschalten der Gasheizung und Umstellung auf Luft-Luft-Wärmepumpen.
Senkung der elektrischen Grundlast des Hauses von etwa 5,5 MWh/Jahr auf etwa 4,0 MWh/Jahr durch Austausch ineffizienter Komponenten (der Haus-Server war 12 Jahre alt).
Der alte Renault Scenic Diesel ist weggefallen.
12.000 km/Jahr bei 7 l/100 km waren 840 Liter Diesel, also grob 8,4 MWh Primärenergie.
Der Megane braucht etwa 14 kWh/100 km im Sommer und 18 kWh/100 km im Winter.
Das sind ungefähr 2 MWh elektrische Energie pro Jahr.
Die Solaranlage produziert etwa 7 MWh/Jahr.
In den Niederlanden wirkt Net Metering bis Ende 2026 noch wie eine virtuelle Batterie:
eingespeiste kWh werden für das Intervall Juli-Juni des Folgejahres gegen bezogene kWh gerechnet.
Die eingespeiste Solarproduktion wird also voll auf den Verbrauch angerechnet.
Installiert sind zwei Panasonic-Multisplit-Systeme.
An der Südseite:
Panasonic RAC Free Multi 5-Port BU R32
9,00 kW Kühlen
10,40 kW Heizen
An der Nordseite:
Panasonic RAC Free Multi 3-Port BU R32
5,20 kW Kühlen
6,80 kW Heizen
Innen hängen sieben Etherea-Wandgeräte mit WLAN:
3x 1,6 kW Kühlen / 2,6 kW Heizen
4x 2,5 kW Kühlen / 3,6 kW Heizen
Dazu kommt ein Panasonic Aquarea DHW Wärmepumpenboiler mit 200 Litern.
Das ursprüngliche Angebot enthielt 270 Liter; wir haben auf 200 Liter reduziert.
Die Außengeräte versorgen die Innengeräte mit Strom, Kältemittel-Vor- und Rücklauf sowie Kondensatableitung.
Dafür braucht jedes Innengerät einen Wanddurchbruch von etwa 5 bis 8 cm.
Durch den laufen Stromkabel, zwei dünne Kupferrohre und ein Kondensatschlauch.
Der Durchbruch wird danach wieder isoliert und innen vom Gerät verdeckt.
Teileliste und Preise aus dem Angebot, ohne Mehrwertsteuer.
Die Wärmepumpenanlage selbst lag bei etwa 17.700 Euro inklusive Installation.
Davon waren rund 5.000 Euro Arbeitskosten.
Dazu kamen Arbeiten, die nicht direkt Wärmepumpe sind, aber in der Praxis zu diesem Umbau gehörten:
neue HRV, also mechanische Hauslüftung mit Wärmezurückgewinnung von Duco;
Bau eines Dachbodens als Zwischendecke mit Isolierung;
komplette Erneuerung des Sicherungskastens;
späteres Entfernen der Radiatoren und des Gasbrenners.
Am Ende sind etwa 25.000 Euro abgeflossen.
Das waren ungefähr 5% des Hauswerts.
Nicht wenig, aber für das Ergebnis auch nicht absurd.
Der Sicherungskasten war von 2002 und über Jahre inkrementell erweitert worden:
Solar, Ladeanschluss, Klima, Zusatzteile auf die Wand.
Das war selbst nach niederländischem Maßstab nicht mehr tragbar.
Die Kontoauszüge legen nahe, daß die Erneuerung des Sicherungskastens etwa 2.500 Euro gekostet hat.
Der lokale Satz lag bei 70 Euro/Stunde.
3 x 8 Stunden Elektrikerarbeit wären also 1.680 Euro netto.
In den Niederlanden gibt es kein deutsches Zunftsystem und keine so strenge Trennung nach Gewerken.
Die Arbeiten hat ein Unternehmer gemacht, der Klimatechnik, Trockenbau, Elektro und noch ein bischen abdeckt:
Flink Duurzaam
.
Das ist quasi ein neues, modernes Gewerk: Nämlich ganzheitliche Energiesanierung von Häusern.
Plan des neuen Sicherungskastens.
Das spätere Entfernen der alten Heizung war noch einmal ein eigener Eingriff.
Die Radiatoren vor den Fenstern wurden abgeflext und entfernt, der Gasbrenner kam raus.
Das hat in den Räumen spürbar Platz geschaffen und die Hauswirtschaftskammer unter dem Dach etwa zur Hälfte freigemacht.
Das Kündigen des Gasliefervertrages war überraschend zäh.
Auch ohne Gasverbrauch liefen Bereitstellungskosten von ziemlich genau 1 Euro pro Tag.
Der Zähler ist jetzt stillgelegt.
Aus dem P1-Interface des Stromzählers kommen im Home Assistant jetzt keine Gas-Pakete mehr, nur noch Strom-Pakete.
Die Anlage ist für +45 Grad bis -15 Grad spezifiziert.
Bei -10 Grad wird sie aber deutlich ineffizient.
Eine solche Nacht hatten wir im Januar: zusammen 45 kWh für die Heizung und 88 kWh für das ganze Haus, weil auch das Auto geladen werden mußte.
Wer in einer Gegend mit längeren tiefen Minusgraden lebt, ist mit einer Luft-Wasser-Wärmepumpe, Pufferspeicher und Heizstab vermutlich besser bedient.
Die kann dann aber nicht trivial kühlen, weil Kondensat behandelt werden muß.
EDIT: Weil es im Fedi immer wieder diskutiert wird.
Man kann theoretisch mit einer Wärmepumpe und einer Fußbodenheizung oder Radiatoren kühlen. Jedenfalls kann eine Luft-Wasser-Wärmepumpe auch invers laufen und kaltes Wasser produzieren, das man dann in den Heizkreislauf pumpt.
Dabei kommt es aber zur Bildung von Konsensat, falls die kältesten Stellen des Heizkreislaufes (also gleich hinter der Wärmepumpe) kälter als der aktuelle Taupunkt (plus 3ºC Marge) werden. Meist heißt das, dass man zum Beispiel bei 17ºC Taupunkt kaltes Wasser von 20ºC erzeugen kann, welches dann mit sagen wir 22ºC in den Radiatoren oder den Fußbodenheizungs-Schleifen ankommt. Man wird einen Ventilator brauchen, um die Schichtung zu durchbrechen und der Wärmetransport hält sich in Grenzen. Es ist besser als gar keine Kühlung, aber es ist nicht sehr leistungsfähig im Vergleich zu einer Luft-Luft-Wärmepumpe (aka Split-Airco).
Es ist außerdem wirkungslos bei Wärme mit hohem Taupunkt, also bei schwülem Wetter, wo eine Split-Airco im Trockungsbetrieb aggressiv das Wasser aus der Luft zieht ohne die Temperatur viel zu senken.
Eine Split-Airco ist dagegen anders beschränkt: Sie kann im Winter nicht mit einem Heizstab unterstützt werden. Wenn die untere Temperaturgrenze der Anlage nicht reicht, braucht man eine andere Zusatzheizung.
Alle Wärmepumpen werden am unteren Ende ihres Spezifikationsbereichs ineffizienter.
Bei Luft-Wasser-Anlagen legt man deshalb auf einen großzügigen Durchschnitt aus und läßt sehr kalte Tage selten vom Heizstab abfangen.
Der Heizstab ist dann zwar nur 100% effizient, läuft aber kaum, und die auf den Durchschnitt statt den Extremwert skalierte Anlage macht das an den nicht so kalten Tagen durch höhere Effizienz wieder wett.
Generell gilt als Faustregel:
Bei weniger als 100 kWh/(m² Jahr) Heizenergiebedarf kann eine Wärmepumpe meist stressarm installiert werden.
Bei mehr als 100 kWh/(m² Jahr) sind Energiesparmaßnahmen wichtiger.
Unser Haus lag vorher bei etwa 1.000 bis 1.200 m³ Gas pro Jahr, also 10 bis 12 MWh.
Bei 156 m² sind das etwa 64 bis 77 kWh/(m² Jahr).
Der zentrale Begriff ist der Hub.
Die Wärmepumpe muß eine Temperatur von einem Eingangswert auf einen Ausgangswert anheben:
zum Beispiel von 5 Grad Außenluft auf 45 Grad Vorlauf.
Das sind 40 Grad Hub.
Diesen Hub zu verringern ist der Kern der Effizienz.
Bei einer Luft-Wasser-Wärmepumpe heißt das meistens: Vorlauf runter.
In einem Berliner Altbau würde ich vorhandene Rippenheizkörper vermutlich durch Typ-33-Heizkörper ersetzen lassen und in einigen Räumen generell mehr Fläche installieren.
Wenn man im kältesten Raum die Heizkörper aufrüstet und dadurch den Vorlauf absenken kann, hilft das dem ganzen Haus.
Klimageräte sind hier “verschweint effizient”, weil der Hub klein ist.
Sie müssen nicht Wasser auf Vorlauftemperatur bringen, sondern Innenluft zwangsbelüftet auf die Zieltemperatur plus etwas Reserve.
Es muß keine Konvektion über Radiatoren unterhalten werden.
Der Nachteil ist Schichtung.
Warme Luft steigt, kalte Luft sinkt.
Das gibt es bei Radiatoren auch, aber dort gibt es keinen Ventilator, der die Luft aktiv mischt.
Niedrige Räume sind für Luft-Luft deshalb besser als Altbauzimmer mit 3,5 m Deckenhöhe.
Wir mußten das Haus stockwerkweise in Temperaturzonen unterteilen.
Sonst fällt kalte Luft ins Erdgeschoss, oder die ganze warme Luft sammelt sich im Dachgeschoss und der Rest bleibt kalt.
Man kann das mit Türen oder mit Umbauten an Treppenhäusern lösen.
Bei uns reichen an einigen Stellen Vorhänge.
Eine Luft-Luft-Wärmepumpe hat praktisch keine thermische Trägheit.
Die Lufttemperatur reagiert binnen Minuten.
Möbel, Wände und andere Massen brauchen Stunden bis einen Tag, bis sie thermisch nachgezogen haben.
Das merkt man daran, daß die Temperatur nach kurzem Betrieb schnell wieder auf den alten Wert zurückfällt.
Im Winter ist genau diese geringe Trägheit angenehm.
Man kommt morgens in ein 18 Grad warmes Wohnzimmer und hat es in weniger als zehn Minuten angenehm.
Es dauert länger, bis die Wärme in Möbel und Wände eingezogen ist, aber Frühstück im Erdgeschoss ist sofort besser.
Im Sommer ist es noch deutlicher:
Die Westseite und das Dachgeschoss bleiben unter 24 Grad.
Für einen Arbeitsplatz unter dem Dach, der vorher gerne auch mal 35 Grad am Platz hatte, ist das kein Komfortdetail, sondern der Unterschied zwischen benutzbar und unbenutzbar.
Die Innengeräte haben mehrere Betriebsarten, darunter “Quiet”.
In dieser Einstellung wird die Lüfterdrehzahl begrenzt.
Dann hört man den Lüfter bestenfalls flüstern.
Wenn die Lamellenverschwenkung aktiv ist, ist die Mechanik lauter als der Lüfter in Quiet.
Am Ende bleibt es aber ein Lüfter.
Er bewegt Luft.
Wer das nicht mag, braucht eine Radiatorheizung mit Wärmepumpe.
Die kann dann aber nicht kühlen.
Die alte Gasheizung brauchte je nach Jahr 1.000 bis 1.200 m³ Gas, also 10 bis 12 MWh Primärenergie.
Nach der Umstellung liefen durch die Klimageräte:
3.370 kWh für Heizung und Kühlung auf der Südseite;
469 kWh auf der Nordseite.
Zieht man die Kühlung ab, landen wir bei etwa 3.500 kWh für Heizung.
Dazu kommen etwa 800 kWh für Brauchwasser.
Monatlicher Stromverbrauch der Klimageräte. Der größte Teil fällt im Winter auf der Südseite an.
Der Gesamtbedarf sieht damit so aus:
4,0 MWh Haus
+3,5 MWh Heizung
+0,8 MWh Warmwasser
+2,0 MWh Auto
=10,3 MWh Gesamtbedarf
Dem stehen etwa 7 MWh Solarertrag gegenüber.
Unter Net Metering haben wir also etwa 3,3 MWh Strom bezahlt.
Das sind deutlich unter 1.000 Euro Gesamtenergiekosten pro Jahr, inklusive Fahren.
Ohne Net Metering sieht die Rechnung anders aus:
7 MWh produziert, 4 MWh eingespeist, 7,3 MWh bezogen.
Dann würden 7,3 MWh Strom bezahlt, also grob 1.800 Euro im Jahr bei einem Vertrag mit Festkosten.
Das ist immer noch nicht extrem teuer, aber es ist nicht mehr dieselbe einfache Jahresbilanz.
Eine Batterie kommt im August.
Geplant sind 30 kWh als Teil einer VPP, also einer Virtual Power Plant.
Der Lieferant der Solaranlage, des Ladeanschlusses, der Batterie und des Stroms kann die Batterie aus Solar oder aus dem Netz laden und ins Haus oder ins Netz entladen, je nachdem, was wirtschaftlich besser ist.
In Deutschland würde man sagen: Die Batterie wird netzdienlich betrieben.
Eine 30-kWh-Batterie für ein Haus mit 350 bis 400 W Nachtgrundlast wäre als reine Eigenverbrauchsbatterie Quatsch.
Acht Monate im Jahr kann der Tagesertrag der Solaranlage den Akku nicht voll machen.
Wenn der Akku aber auch aus dem Netz geladen und wieder ins Netz abgegeben wird, kann das sinnvoll sein.
Wie lange hält so ein Akku?
Wenn das Auto lädt: weniger als 3 Stunden.
Das Auto zieht 11 kW.
30 kWh sind bei 11 kW in unter 3 Stunden weg.
Im Sommer: etwa 3 Tage.
Im Winter bei etwa 0 Grad draußen: 0,75 bis 1,25 Tage.
Bei 2.000 W Heizleistung im Haus und 400 bis 600 W Grundlast gehen rund 2.500 W ins Haus.
Eine 10-kWh-Batterie ist dann in 4 Stunden leer, eine 30-kWh-Batterie in 12 Stunden.
Am 11. März, einem normalen kühlen Tag mit 8 bis 9 Grad, zog die Südseiten-Anlage 400 bis 800 W.
Das Haus lag damit vermutlich bei 800 bis 1.200 W total.
Bei 10 kWh kommt man damit etwa 10 Stunden hin, bei 30 kWh etwa 30 Stunden.
Leistungsaufnahme der Südseiten-Anlage am 11. März 2026: meist 400 bis 800 W.
Perioden mit sehr hohen Stundenpreisen dauern typischerweise 2 bis 4 Stunden.
Schon 10 kWh reichen, um solche Phasen zu überbrücken, solange man in dieser Zeit nicht das Auto laden will.
Die wichtige Regel bleibt:
Erst messen, dann planen.
Ohne Messwerte schätzt man schlecht und kauft sich Angstprodukte.
Die Lebensqualität ist deutlich besser.
Das Haus ist im Winter schnell warm, im Sommer kühlbar, und Gas ist weg.
Die Umstellung hat den Energiebedarf nicht verschwinden lassen.
Sie hat ihn von Gas und Diesel auf Strom verschoben und die Effizienz erhöht,
also die Primärenergie deutlich verkleinert.
Dazu kommt der Eigenverbrauch selbst generierten Stromes aus der Solaranlage, der die Kostendeckung noch weiter erhöht.
Das ist genau der Punkt:
Strom ist messbar, lokal teilweise selbst erzeugbar und mit Batterie zeitlich verschiebbar.
Die nächste Optimierung ist nicht mehr die Heizung.
Die funktioniert.
Die nächste Optimierung ist Timing:
mehr eigenen Solarstrom selbst nutzen, teure Stunden überbrücken und nach Ende von Net Metering nicht unnötig viel Strom durch das Netz hin und her schieben.
The Valuable News weekly series is dedicated to provide summary about news, articles and other interesting stuff mostly but not always related to the UNIX/BSD/Linux systems. Whenever I stumble upon something worth mentioning on the Internet I just put it here.
Today the amount information that we get using various information streams is at massive overload. Thus one needs to focus only on what is important without the need to grep(1) the Internet everyday. Hence the idea of providing such information ‘bulk’ as I already do that grep(1).
The Usual Suspects section at the end is permanent and have links to other sites with interesting UNIX/BSD/Linux news.
Past releases are available at the dedicated NEWS page.
I just got Victoria Logs running. Now I want to get logs into it. For starters, I want to get the logs on the host itself into Victoria Logs. I figure this is a log-risk experiment.
However, this post has been deprecated by a newer post which covers more material.
In this post:
FreeBSD 15.0
victoria-logs-1.50.0_2
syslog-ng-4.11.0_2
I will be using TLS between syslog-ng and victoria-logs – you will notice this is all on the same host, and some of you might say: you don’t need TLS for that. However, this is a proof-of-concept for remote hosts. They will be passing traffic through my VPN and my network. Or perhaps over the Internet. Things change. Let’s start with TLS.
The install
I installed:
[20:08 logs dvl ~] % sudo pkg install syslog-ng
Updating local repository catalogue...
[logs.int.unixathome.org] Fetching meta.conf: 100% 179 B 0.2 kB/s 00:01
[logs.int.unixathome.org] Fetching data: 100% 352 KiB 360.5 kB/s 00:01
Processing entries: 100%
local repository update completed. 953 packages processed.
All repositories are up to date.
The following 7 package(s) will be affected (of 0 checked):
New packages to be INSTALLED:
glib: 2.86.4,2 [local]
ivykis: 0.43.2_1 [local]
json-c: 0.18 [local]
libuuid: 2.42.1 [local]
py314-packaging: 26.2 [local]
python314: 3.14.6 [local]
syslog-ng: 4.11.0_2 [local]
Number of packages to be installed: 7
The process will require 360 MiB more space.
53 MiB to be downloaded.
Proceed with this action? [y/N]: y
[logs.int.unixathome.org] [1/7] Fetching ivykis-0.43.2_1: 100% 70 KiB 71.3 kB/s 00:01
[logs.int.unixathome.org] [2/7] Fetching py314-packaging-26.2: 100% 203 KiB 208.0 kB/s 00:01
[logs.int.unixathome.org] [3/7] Fetching glib-2.86.4,2: 100% 11 MiB 11.0 MB/s 00:01
[logs.int.unixathome.org] [4/7] Fetching syslog-ng-4.11.0_2: 100% 1102 KiB 1.1 MB/s 00:01
[logs.int.unixathome.org] [5/7] Fetching libuuid-2.42.1: 100% 48 KiB 49.2 kB/s 00:01
[logs.int.unixathome.org] [6/7] Fetching json-c-0.18: 100% 71 KiB 73.1 kB/s 00:01
[logs.int.unixathome.org] [7/7] Fetching python314-3.14.6: 100% 41 MiB 42.6 MB/s 00:01
Checking integrity... done (0 conflicting)
[logs.int.unixathome.org] [1/7] Installing ivykis-0.43.2_1...
[logs.int.unixathome.org] [1/7] Extracting ivykis-0.43.2_1: 100%
[logs.int.unixathome.org] [2/7] Installing json-c-0.18...
[logs.int.unixathome.org] [2/7] Extracting json-c-0.18: 100%
[logs.int.unixathome.org] [3/7] Installing libuuid-2.42.1...
[logs.int.unixathome.org] [3/7] Extracting libuuid-2.42.1: 100%
[logs.int.unixathome.org] [4/7] Installing python314-3.14.6...
[logs.int.unixathome.org] [4/7] Extracting python314-3.14.6: 100%
[logs.int.unixathome.org] [5/7] Installing py314-packaging-26.2...
[logs.int.unixathome.org] [5/7] Extracting py314-packaging-26.2: 100%
[logs.int.unixathome.org] [6/7] Installing glib-2.86.4,2...
[logs.int.unixathome.org] [6/7] Extracting glib-2.86.4,2: 100%
[logs.int.unixathome.org] [7/7] Installing syslog-ng-4.11.0_2...
[logs.int.unixathome.org] [7/7] Extracting syslog-ng-4.11.0_2: 100%
==> Running trigger: glib-schemas.ucl
Compiling glib schemas
No schema files found: doing nothing.
==> Running trigger: gio-modules.ucl
Generating GIO modules cache
=====
Message from python314-3.14.6:
--
Note that some standard Python modules are provided as separate ports
as they require additional dependencies. They are available as:
py314-gdbm databases/py-gdbm@py314
py314-sqlite3 databases/py-sqlite3@py314
py314-tkinter x11-toolkits/py-tkinter@py314
=====
Message from syslog-ng-4.11.0_2:
--
syslog-ng is now installed! To replace FreeBSD's standard syslogd
(/usr/sbin/syslogd), complete these steps:
1. Create a configuration file named /usr/local/etc/syslog-ng.conf
(a sample named syslog-ng.conf.sample has been included in
/usr/local/etc). Note that this is a change in 2.0.2
version, previous ones put the config file in
/usr/local/etc/syslog-ng/syslog-ng.conf, so if this is an update
move that file in the right place
2. Configure syslog-ng to start automatically by adding the following
to /etc/rc.conf:
syslog_ng_enable="YES"
3. Prevent the standard FreeBSD syslogd from starting automatically by
adding a line to the end of your /etc/rc.conf file that reads:
syslogd_enable="NO"
4. Shut down the standard FreeBSD syslogd:
kill `cat /var/run/syslog.pid`
5. Start syslog-ng:
/usr/local/etc/rc.d/syslog-ng start
[20:32 logs dvl ~] %
Configuration tweaks & permissions issues
I added this section after publishing the post. There are some permission issues and local logging issues for me to fix. This is how I did that.
By default, syslog-ng does a chmod 0700 when it opens the file. I wanted to preserve existing permissions, mostly for logcheck usage, but also for my sanity. Here are those changes:
That did not help. What did help was this search: sending syslog-ng to victorialogs
That brought up this AI Overview from Google (don’t use this, instead, see Getting Nginx logs into Victoria-Logs where I also cover regular non-Nginx logs):
# Define the VictoriaLogs target destination
destination d_victorialogs {
network("your-victorialogs-server-ip" port(29514) transport("tcp"));
};
# Log path linking your sources to VictoriaLogs
log {
source(s_sys); # Use your existing system source name here
destination(d_victorialogs);
};
I used this in /usr/local/etc/syslog-ng.conf:
destination d_victorialogs {
network("logs.int.unixathome.org" port(29514) transport("tcp"));
};
# Log path linking your sources to VictoriaLogs
log {
source(src); # Use your existing system source name here
destination(d_victorialogs);
};
Notes:
I changed your-victorialogs-server-ip to logs.int.unixathome.org
source(s_sys) was modified to match the default syslog_ng configuration: source(src)
TLS?
Not shown, but if you want TLS and have told VictoriaLogs to provide TLS, the above configuration becomes:
The first three clauses on that string were pulled from the default value for victoria_logs_args as found in /usr/local/etc/rc.d/victoria-logs.
I restarted syslog_ng, ran a logger test and data started showing up. As shown here:
victoria-logs first data
Log rotation
Originally, I thought I needed to do this, but it’s wrong. syslog-ng uses /var/run/syslog.pid which means changes like this are not required.
Don’t do this:
I also added /var/run/syslog-ng.pid to the end of each line in /etc/newsyslog.conf – I was seeing some permission issues on the logs. Time will tell if this change fixes that.
Now, let’s convert that into something syslog-ng can use.
Getting raw metrics
This section is just FYI.
At one point, the debugging led me to running this query. Over time, I could see that none of these metrics were changing. That helped me to confirm that data wasn’t getting there. Something else was wrong.
This is the configuration on the nginx instance which will be sending logs to Victoria-Logs.
EDIT: Since writing this post, I’ve added host to the format specification.
# this defines the format Nginx will save to disk.
log_format victorialogs_json escape=json '{'
'"_time":"$time_iso8601",'
'"_msg":"$request",'
'"status":"$status",'
'"remote_addr":"$remote_addr",'
'"body_bytes_sent":"$body_bytes_sent",'
'"request_time":"$request_time",'
'"http_user_agent":"$http_user_agent",'
'"_stream.app":"nginx",'
'"http_referer":"$http_referer",'
'"request_method":"$request_method",'
'"host":"$host",'
'"hostname":"$hostname",'
'"server_name":"$server_name"'
'}';
# the above goes outside the vhost definition.
# the following goes inside the vhost
# the regular logs, already in place
error_log /var/log/nginx/freshports.org-error.log;
access_log /var/log/nginx/freshports.org-access.log combined;
# the addition, which syslog-ng will read
access_log /var/log/nginx/access_json.log victorialogs_json;
syslog-ng config
This is the syslog-ng config, which is configured for TLS.
EDIT: Similarly, as above, host was added to the body after first publishing this post.
parser p_json {
# Read the JSON from $MESSAGE because flags(no-parse) leaves $MSG empty
json-parser(prefix(".json."));
};
source s_nginx_json {
file("/var/log/nginx/access_json.log" flags(no-parse));
};
destination d_victorialogs_json {
http(
url("https://logs.int.unixathome.org:9428/insert/jsonline")
method("POST")
headers("Content-Type: application/x-ndjson")
body("{\"_msg\":\"${.json._msg}\",\"_time\":\"${.json._time}\",\"_stream.app\":\"${.json._stream.app}\",\"status\":\"${.json.status}\",\"remote_addr\":\"${.json.remote_addr}\",\"body_bytes_sent\":\"${.json.body_bytes_sent}\",\"http_user_agent\":\"${.json.http_user_agent}\",\"request_time\":\"${.json.request_time}\",\"request_method\":\"${.json.request_method}\",\"host\":\"${.json.host}\",\"hostname\":\"${.json.hostname}\",\"server_name\":\"${.json.server_name}\"}\n")
tls(
peer-verify(yes)
)
# LOG LOSS PROTECTION:
disk-buffer(
disk-buf-size(1073741824) # 1 GB max buffer storage size
reliable(yes) # Synchronous disk writes protect against power loss
)
workers(2)
);
};
log {
source(s_nginx_json);
parser(p_json);
destination(d_victorialogs_json);
};
In short, syslog-ng is tailing the log, which is already in JSON, then pulling fields out, and putting them into the fields which Victoria-Logs expect. The data is transmitted via https.
General syslog configuration
For the general syslog messages, not just nginx, these are my settings.
These are the settings I added to /etc/rc.conf so Victoria-Logs will present an incoming TLS connection. Again, this was all on one line.
This post is more self-documentation than anything else. The links in this post might be useful than the content.
However, this post has been deprecated by a newer post which covers more material.
Today I’ll start pulling production FreshPorts nginx logs into VictoriaLogs. Over the past few days, I’ve configured a proof-of-concept and now I’m ready to try this in prod.
In this post:
FreeBSD 15.0 (installed on the host aws-1)
nginx-1.30.2_2,3 (running in a jail, aws-1-nginx01, on the host aws-1)
syslog-ng-4.11.0_2 (running on the host aws-1, pulling logs from the jail)
Good. Now let’s get syslog-ng sending data to that host.
nginx json logs
It is rather easy to get syslog-ng to send JSON logs and VictoriaLogs is quite happy to ingest them. This seems to be both the recommended and the easiest approach.
To the nginx config in the jail (of aws-1-nginx01), I followed that Getting Nginx logs into Victoria-Logs for the nginx configuration. I won’t duplicate that here.
VictoriaLogs is feature rich, which means at this point, I know very little about it.
However, this post has been deprecated by a newer post which covers more material.
I do know that the original syslog-ng configuration I supplied in Getting Nginx logs into Victoria-Logs is now less complicated. With the help of duck.ai, I managed to reduce it. Now it’s sending the json without running it through a parser.
In this post:
FreeBSD 15.1
syslog-ng-4.11.0_2
victoria-logs-1.50.0_2
The original configuration
The original configuration from the above post looked like this:
parser p_json {
# Read the JSON from $MESSAGE because flags(no-parse) leaves $MSG empty
json-parser(prefix(".json."));
};
source s_nginx_json {
file("/var/log/nginx/access_json.log" flags(no-parse));
};
destination d_victorialogs_json {
http(
url("https://logs.int.unixathome.org:9428/insert/jsonline")
method("POST")
headers("Content-Type: application/x-ndjson")
body("{\"_msg\":\"${.json._msg}\",\"_time\":\"${.json._time}\",\"_stream.app\":\"${.json._stream.app}\",\"status\":\"${.json.status}\",\"remote_addr\":\"${.json.remote_addr}\",\"body_bytes_sent\":\"${.json.body_bytes_sent}\",\"http_user_agent\":\"${.json.http_user_agent}\",\"request_time\":\"${.json.request_time}\",\"request_method\":\"${.json.request_method}\",\"host\":\"${.json.host}\",\"hostname\":\"${.json.hostname}\",\"server_name\":\"${.json.server_name}\"}\n")
tls(
peer-verify(yes)
)
# LOG LOSS PROTECTION:
disk-buffer(
disk-buf-size(1073741824) # 1 GB max buffer storage size
reliable(yes) # Synchronous disk writes protect against power loss
)
workers(2)
);
};
log {
source(s_nginx_json);
parser(p_json);
destination(d_victorialogs_json);
};
Of note: look at the body directive… all that text manipulation. There is an easier way.
The easier way
This is the new improved super duper syslog-ng configuration.
I just got Victoria Logs running. Now I want to get logs into it. For starters, I want to get the logs on the host itself into Victoria Logs. I figure this is a log-risk experiment.
The nginx logs reside in a jail (nginx01) on that host
I will be using TLS between syslog-ng and victoria-logs – you will notice this is all on the same host, and some of you might say: you don’t need TLS for that. However, this is a proof-of-concept for remote hosts. They will be passing traffic through my VPN and my network. Or perhaps over the Internet. Things change. Let’s start with TLS.
I know that various tools can be used for testing logs to VictoriaLogs. I should investigate that. Filebeat (now known as beats) has been mentioned.
The install
I installed:
[17:03 x8dtu dvl ~] % sudo pkg install syslog-ng
Updating local repository catalogue...
Fetching meta.conf: 100% 179 B 0.2 kB/s 00:01
Fetching data: 100% 353 KiB 361.3 kB/s 00:01
Processing entries: 100%
local repository update completed. 955 packages processed.
All repositories are up to date.
The following 6 package(s) will be affected (of 0 checked):
New packages to be INSTALLED:
glib: 2.86.4,2 [local]
ivykis: 0.43.2_1 [local]
json-c: 0.18 [local]
libuuid: 2.42.1 [local]
py312-packaging: 26.2 [local]
syslog-ng: 4.11.0_2 [local]
Number of packages to be installed: 6
The process will require 112 MiB more space.
12 MiB to be downloaded.
Proceed with this action? [y/N]: y
[1/6] Fetching ivykis-0.43.2_1: 100% 70 KiB 71.3 kB/s 00:01
[2/6] Fetching py312-packaging-26.2: 100% 189 KiB 193.9 kB/s 00:01
[3/6] Fetching glib-2.86.4,2: 100% 10 MiB 5.5 MB/s 00:02
[4/6] Fetching syslog-ng-4.11.0_2: 100% 1102 KiB 1.1 MB/s 00:01
[5/6] Fetching libuuid-2.42.1: 100% 48 KiB 49.5 kB/s 00:01
[6/6] Fetching json-c-0.18: 100% 71 KiB 73.1 kB/s 00:01
Checking integrity... done (0 conflicting)
[1/6] Installing ivykis-0.43.2_1...
[1/6] Extracting ivykis-0.43.2_1: 100%
[2/6] Installing json-c-0.18...
[2/6] Extracting json-c-0.18: 100%
[3/6] Installing libuuid-2.42.1...
[3/6] Extracting libuuid-2.42.1: 100%
[4/6] Installing py312-packaging-26.2...
[4/6] Extracting py312-packaging-26.2: 100%
[5/6] Installing glib-2.86.4,2...
[5/6] Extracting glib-2.86.4,2: 100%
[6/6] Installing syslog-ng-4.11.0_2...
[6/6] Extracting syslog-ng-4.11.0_2: 100%
==> Running trigger: glib-schemas.ucl
Compiling glib schemas
No schema files found: doing nothing.
==> Running trigger: gio-modules.ucl
Generating GIO modules cache
=====
Message from syslog-ng-4.11.0_2:
--
syslog-ng is now installed! To replace FreeBSD's standard syslogd
(/usr/sbin/syslogd), complete these steps:
1. Create a configuration file named /usr/local/etc/syslog-ng.conf
(a sample named syslog-ng.conf.sample has been included in
/usr/local/etc). Note that this is a change in 2.0.2
version, previous ones put the config file in
/usr/local/etc/syslog-ng/syslog-ng.conf, so if this is an update
move that file in the right place
2. Configure syslog-ng to start automatically by adding the following
to /etc/rc.conf:
syslog_ng_enable="YES"
3. Prevent the standard FreeBSD syslogd from starting automatically by
adding a line to the end of your /etc/rc.conf file that reads:
syslogd_enable="NO"
4. Shut down the standard FreeBSD syslogd:
kill `cat /var/run/syslog.pid`
5. Start syslog-ng:
/usr/local/etc/rc.d/syslog-ng start
Configuration tweaks & permissions issues
I added this section after publishing the post. There are some permission issues and local logging issues for me to fix. This is how I did that.
By default, syslog-ng does a chmod 0700 when it opens the file. I wanted to preserve existing permissions, mostly for logcheck usage, but also for my sanity. Here are those changes:
The log_format statement goes outside the server declaration but inside the http directive.
The log directive, as shown below, goes inside the server declaration. I keep the existing original logs (lines 1-2). The new lines are lines 4-5.
error_log /var/log/nginx/freshports.org-error.log;
access_log /var/log/nginx/freshports.org-access.log combined;
# Send JSON format to a log agent or Syslog endpoint handled by VictoriaLogs
access_log /var/log/nginx/access_json.log victorialogs_json;
Issuing a reload (or restart) will start logging to the new file. That has to be done inside the jail, in my case. I think I could do it from outside, but not today.
Checking the log file, I see this (newlines added to fit on a page):
[17:58 x8dtu-nginx01 dvl /usr/local/etc/freshports] % tail -1 /var/log/nginx/access_json.log
{"_time":"2026-06-20T17:59:14+00:00","_msg":"GET /foo/?branch=2026Q2 HTTP/1.1","status":"403","remote_addr":"71.168.156.244","body_bytes_sent":"183","request_time":"0.000",
"http_user_agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 14_3_1) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/131.0.6778.204 Safari/537.36","app":"nginx","http_referer":"","request_method":"GET",
"host":"x8dtu.example.org","hostname":"x8dtu-nginx01.vpn.unixathome.org","server_name":"x8dtu.example.org"}
Good.
Next, we tell syslog-ng to pick up and transmit that file to the server.
Sending nginx logs to the server
The following instructs syslog-ng to send the nginx logs to the server.
In Season 3 sind aktuell bereits wieder 8 Spieler dabei, die um die Vorherrschaft in der Galaxie ringen. Das ist ein guter Anlass für einen Hinweis, der bisher nur am Rande gefallen ist: MMO-20044 ist Open Source.
Der komplette Quellcode steht auf Codeberg unter der AGPL-3.0:
Das Spiel ist in Python geschrieben, FastAPI im Backend, SQLAlchemy für die Datenbank, HTMX im Frontend. Wer wissen will, wie der Tick-Scheduler arbeitet, wie die Forschungsbäume aufgebaut sind oder wie die Piraten ihre Beute verstecken, kann das jetzt nachlesen. Wer einen eigenen Server aufsetzen oder einen Patch beisteuern will, ebenso. Eine README mit Einrichtungshinweisen und eine .env.example liegen bei.
Mir geht es dabei weniger um Sterne auf Codeberg als um Rückmeldungen. Neue Ideen, frische Augen auf den Code, vielleicht ein zweiter Sprachzweig. Wer reinschaut und etwas findet, das besser gelöst werden könnte: Issues und Pull Requests sind willkommen.
I feel bad for missing my schedule earlier this month, but life got int he way, and things have been a tad complicated. But things are still mostly chugging along.
As it became apparent a few months ago, my wife and I left London and moved a little further North, to Milton Keynes. A city that, before moving to England, I only heard mentioned by Terry Pratchett and Neil Gaiman in Good Omens. As it turns out, the choice was in part influenced by having multiple colleagues, including teammates, in the city already, and in part by the fact that the city strikes a balance for one very important aspect: transports.
As you may remember, I still don’t have a driving license. Not entirely for lack of trying: I have passed my theory test now in three countries, including the UK, but I also had limited needs for it. Dublin first, and London second, are cities in which you really don’t want to be driving. And while for Ireland the ability to leave the city is fairly constrained by the access to cars, England and Great Britain have more than decent train and bus connections, so over the seven years I spent in London I have not felt particularly constrained by the lack of a license.
But Milton Keynes is not London. While there is some level of public transport, it is neither as frequent or capillary as London, despite being more expensive. Busses going into and out of the city centre are at least reliable, but if you’re trying to hop between the satellite villages where the majority of the housing is, you’re quite out of luck. The nearest high-street from our house is in a village that is less than 15 minutes drive, but would take over an hour to get there by bus — and two rides, there’s no “Hopper Fare” in Milton Keynes. Which is why I have started a (probably pipe-dream) petition to get a new bus route.
But I did say that there’s a balance to be stricken here, and the answer to that is that Milton Keynes has a terrific, if a bit ran down and in need of further investment, network of pedestrian and cycle roads called Redways. Do not confuse them for the “cycle superhighways” that London has been building into the existing road network over the past ten years or so: these roads are significantly larger, and (for the official part at least) do not cross motor traffic at level at all, going either below or over it.
While not all of the satellite villages are connected directly with the “official” Redways, at the very least the new built areas tend to provide comparable cycle and pedestrian spaces to the side of their main roads. It means that, if you’re okay with long walks, you can safely stroll from a historical village as Stony Stratford to the centre:mk shopping centre in the middle of the city, never having to cross the dual carriageway at level! (There are, though, a few level crossing with side streets as well as the parking lots, which are impractical to avoid. Still, those are definitely more acceptable in my views.)
And this is where I fell in love with the idea of moving to Milton Keynes. While cycling has never been one of my hobbies, talking about it with a friend gave me an interesting idea. My main issue with cycling has always been my personal lack of balance – I’m not sure if it’s an actual physical issue or just a lack of skill, to be honest – but that means a trike (a three-wheels cycle) would make the issue moot for me. Unfortunately, trikes are exceedingly rare to begin with, in no small part because, in London, there’s no way you would be able to ride one on the cycle lane.
But, the Milton Keynes Redways are much wider, designed for families. So I went and looked, and eventually picked up a Cube Family Trike – not because I plan to use it to take kids in it, but because the Electric Bike Shop recommended it over the “Cargo” branded version, which just has a slightly different cover, and costed 20% extra – which is roughly the same width as a two-seater pram, and thus fits comfortably on Redways and similar cycleways in the area.
Why was I looking at a cargo trike, though? Well, as I said I don’t have a license, and neither does my wife. In London, our daily “top up” shopping was either done on the tube and bus, or by walking down to the Sainsbury’s Local corner shop. In our village in Milton Keynes, we currently don’t have an equivalent shop. There is a temporary shop, but the selection, quality, and pricing of the items sold is not great, and it’s not really suitable for the type of top-up shops we found ourselves needing. But there’s a Co-Op just 14 minutes cycle, almost all of which is on pedestrian/cycle shared ways, requiring only three motor traffic level crossings. So when we find ourselves needing something, that’s where I go.
Quite a few people, when they heard about my plan to buy a cargo trike, tried to dissuade me at it. Even the shop (who has been extraordinary in their customer service!) was not convinced I would be happy with it (but I am!) And I sort of see their point, because admittedly, a trike is not the easiest of the cycles to own.
Even though Milton Keynes is so much better than London when it comes to cycleways, the infrastructure is not really “designed” for trikes, obviously. It is rather than trikes are “compatible” for the most part with what is there. But for instance, good luck finding a good way to park and lock your trike. I have at this point learnt which places I feel comfortable enough to just leave the trike alarm “armed”, but they are few and far between, sometimes I find myself taking a car parking space to lock it, as the cycle bays are too small for it.
In one particular case, in an industrial estate where a coffee shop I enjoy is, the cycle parking space is almost perfect: it has a canopy to cover it up at least a bit, it has enough space in-between the locking places that even my trike fits… but then it suffers from two problems: the first is that even though you can see it from the Redway, you can’t reach it until you go all the way around the block, and the second is that the curb isn’t cut, and try as I might, I couldn’t get my trike onto it to lock it. I instead leave the trike in the front of the coffee shop even when I go to the stores (I checked with the owners that it’s okay for me to!)
There’s also a not-great issue when trying to cross the dual carriageway on one side of our village: you get to choose between going through an underpass and having to go uphill in one direction, or you can cross at level with a protected (traffic light) crossing. Except the protected crossing has an island in the middle, and my trike can’t turn into it. I did it once, feared for my life, and now take the underpass.
And, frankly speaking, the economics are not there, again almost certainly because there’s so little market for these. When I pre-ordered the trike in London, they did accept holding it for me for nearly six months (until we received the keys to the garage to safely store it in!) because they knew it would be unlikely they would sell it anyway — turns out they were wrong with that, they did sell it (but since I was not in a rush to receive it, everything was fine.) But that means there’s only a handful of these trikes in England, as they are, to my understanding, the only retailer holding them at least in London.
Cube is a German company, and while their ebike products are much closer to affordable, their etrike are still niche products. You can see how part of the trike frame is re-purposed from their bikes, including the in-tube storage, which takes the place of the battery (the trike has two battery bays under the cargo, though I only have one battery on mine, I don’t need that long of a range.) Thankfully most of everything that is specific to the trike is well engineered and implemented. The most annoying part is the Kiox display unit, that is supplied directly by Bosch. While the small display is meant to be able to handle turn-by-turn navigation with a compatible app, my experience with it has been quite terrible. I’m glad I took the suggestion of buying a Garmin bike computer instead, as its navigation is significantly more reliable, even if the UX itself is not something i’m raving about.
Speaking of navigation, Google Maps is completely useless in this part of England, when it comes to cycling (and to be honest also still a bit broken even just to find stores!) Despite the presence of Redways, Google tries to send you through dual carriageways when cycling. I have asked a few suggestions of other cyclists, and after trying a few I settled on Komoot. It integrates nicely with both Garmin (using their GPS) and Bosch’s own computer (for recording trips when I don’t need directions), and I believe leverages OpenStreetMap, which is much more aware of local conditions, and allows me to properly plan a nice bike ride out there.
With this taken care of, the feeling of freedom of being able to just grab the bike and go is actually quite exhilarating. And it has been very useful to have, particularly as for the first few months after moving in, we couldn’t get deliveries to the house from Evri, and I had instead to go up to a not-so-local shop to pick them up. And even after that, one delivery driver decided to not even try, and have me ride to the other side of Western Milton Keynes to pick it up, through a muddy trail that I’m not going to ride through again (I’m lucky my trike didn’t end up getting stuck in the mud, that was not a fun ride, and on the way back I updated Komoot to avoid that particular trail, it only did that because the main road that connects us to that side of the city is still not open, and the more bearable path is just… longer.)
If anything, the larger problem I found with having a cargo trike rather than a normal bike is that the accessories ecosystem is a bit more barebone. I’m using a GoPro as a dash cam (which doubled as a touristy action cam when we last visited Taiwan), but I looked at front-and-back bike dashcams before, but none are suitable to be positioned on the back of the cargo bay. Similar for bike lights, although the trike has already suitable lights wired in, which makes it a bit of a moot point (plus I only ever used the bike in the dark to pick up pizza at our local truck, and that truck is gone unfortunately.)
Anyway, so it is, my cycling story began, making me a bloke on a trike.





 tenure.
tenure.